Can LLMs Detect Benchmark Defects?
A Meta-Benchmark from Benchmark Version Diffs
Every major coding benchmark has released an updated version acknowledging substantial defects. We collected these author-acknowledged defects as ground truth and tested whether LLMs can find them automatically. The answer is partial. It is meaningful for triage, but far from replacing human auditors.
The Problem
Coding agent benchmarks are the foundation of AI progress in software engineering. They drive training signal for RL, provide evaluation metrics for model releases, and shape research priorities. But these benchmarks themselves contain bugs.
- SWE-bench: OpenAI audited 1,699 tasks with 3 annotators each. 68% were flagged as defective: underspecified problem statements, tests that reject valid solutions, and other issues. This led to SWE-bench Verified (500 curated tasks).
- Terminal-Bench 2: 31% of tasks were revised via community and author fix PRs, covering weak tests, misleading artifacts, and environment issues.
- Terminal-Bench 1: 108 community fix PRs covering 129 defect entries across 229 tasks as of May 2026.
These defects persist not from lack of effort but because manual auditing doesn't scale. And stronger agents surface new defects. When frontier models saturated SWE-bench Verified, auditing the remaining failures revealed that 59% stemmed from flawed tests, not model limitations.
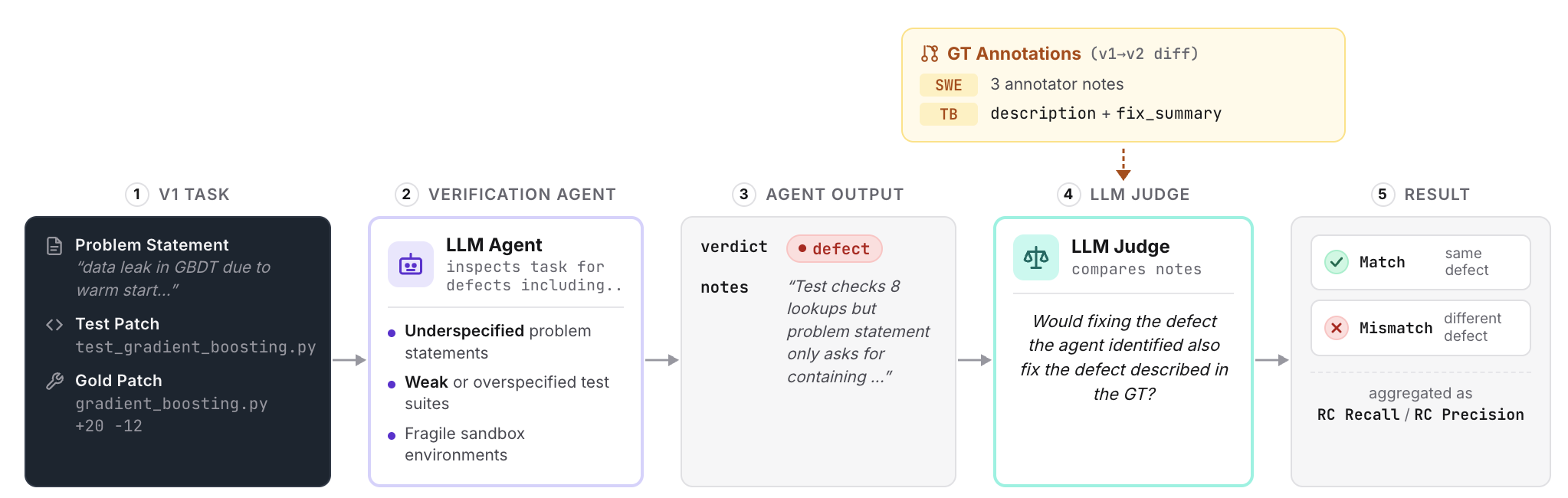
Task Verification Bench
We introduce Task Verification Bench (TVB), a meta-benchmark that repurposes benchmark version diffs as ground truth. When benchmark authors release v2, they implicitly label each modified task as “defective in v1.”
We collected labels from three benchmark lineages:
- SWE-bench: 1,160 defect tasks from 3-annotator audit (after filtering: 129 defect + 129 valid = 258 tasks)
- Terminal-Bench 2: 26 defect + 26 valid = 52 tasks
- Terminal-Bench 1: 65 defect + 56 valid = 121 tasks (after GT noise filtering)

Given only the original task artifacts (problem statement, test suite, gold patch), the LLM agent must determine whether each task contains a defect and identify the correct root cause.
Root-Cause Matching
A key design choice: we evaluate with root-cause matching, not just binary detection.
An agent that flags a task as defective but for the wrong reason provides no actionable signal for fixing it. We require the agent's identified defect to match the ground truth annotation. An LLM judge compares the agent's notes against GT and asks: would fixing the agent's identified defect also fix the GT defect?
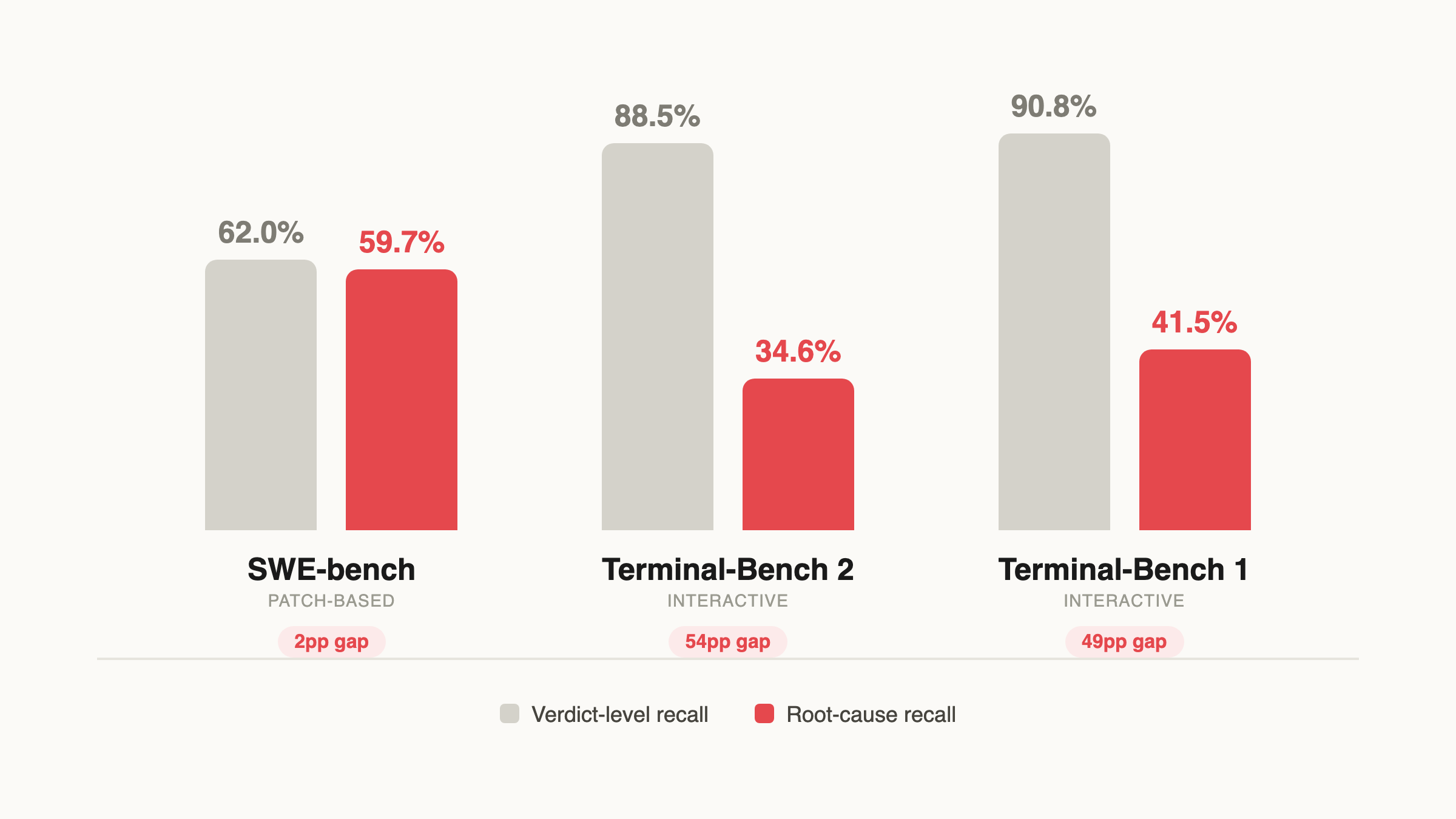
This distinction matters enormously. Verdict-level recall overestimates true detection by up to 54 percentage points.
Key Results
Cross-Benchmark Baseline (GPT-5.4, verify-only with sandbox)
| SWE-bench | TB2 | TB1 | |
|---|---|---|---|
| Verdict Recall | 62.0% | 88.5% | 90.8% |
| RC Recall | 59.7% | 34.6% | 41.5% |
| Verdict→RC Gap | 2pp | 54pp | 49pp |
35–60% root-cause-matched recall: meaningful for triage, but far from fully automated auditing.
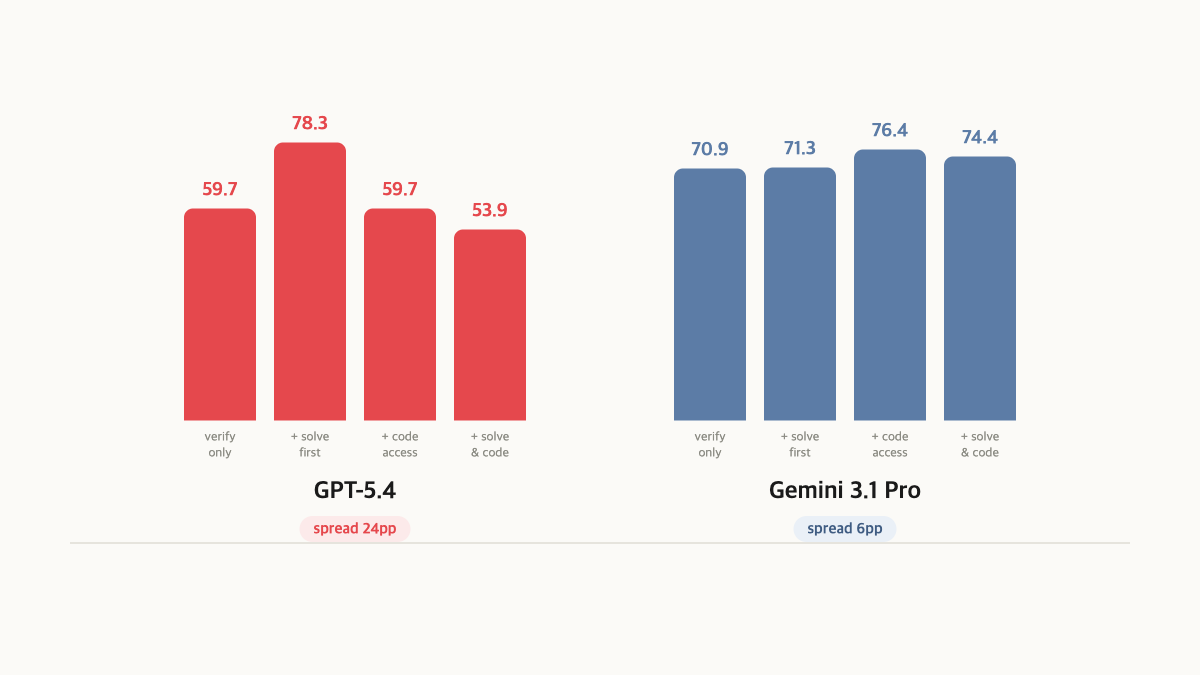
Self-Attribution Anchoring
Pipeline ablation on SWE-bench uncovered a surprising effect. When GPT-5.4 solves a task and then verifies with sandbox access to its own failed code, it blames itself rather than the benchmark, dropping RC recall from 78.3% to 53.9%.
We call this self-attribution anchoring. The agent reviews its failed patch, attributes the test failure to its own implementation, and dismisses defects it would otherwise flag.
Gemini 3.1 Pro resists this effect entirely, maintaining stable 70–76% RC recall across all conditions. Model choice matters more than pipeline design.
Text-Layer vs Infrastructure-Layer
The agent excels at text-layer defects, comparing problem statements against test assertions to find explicit mismatches. But it exhibits an infrastructure-layer blind spot: environment issues, Dockerfile leakage, and oracle regressions require longer reasoning chains that the agent consistently fails to follow.
All 6 sampled true positive cases involve text-layer defects. All 8 Terminal-Bench miss/mismatch cases involve infrastructure-layer defects.
Implications
LLM-assisted auditing can meaningfully reduce human review effort for text-layer defects. But infrastructure-layer verification remains a challenge requiring human expertise.
The optimal workflow is agent-first triage followed by targeted human review. LLMs prioritize where humans should look, rather than replacing them.
This is the workflow we're building at Delphik.
Read the Paper
“Can LLMs Detect Benchmark Defects? A Meta-Benchmark from Benchmark Version Diffs”
Accepted to the DL4C Workshop @ ICML 2026.
Task Verification Bench dataset and evaluation code will be released upon publication.
About the Author
Jongwon Park is the founder of Delphik, building eval infrastructure for AI coding agents. Previously an RL research engineer at Krafton (PUBG) and AI lead managing 300+ data labelers.