LLM이 벤치마크 결함을 찾을 수 있는가?
버전 Diff 기반 Meta-Benchmark
주요 코딩 벤치마크는 하나같이 결함을 인정하며 업데이트 버전을 내놓았습니다. 이렇게 저자가 인정한 결함을 ground truth로 모으고, LLM이 그걸 자동으로 찾아낼 수 있는지 실험했습니다. 결론은 이렇습니다. 어느 정도는 가능하지만, 사람을 완전히 대체하기엔 아직 부족합니다.
문제
코딩 에이전트 벤치마크는 AI 발전의 핵심 도구입니다. RL 학습 신호를 만들어 주고, 모델 출시 때 성능 지표가 되고, 연구 방향까지 정합니다. 그런데 이 벤치마크 자체에 버그가 있습니다.
- SWE-bench: OpenAI가 1,699개 task를 annotator 3명씩 붙여 감사했더니 68%가 결함으로 판정됐습니다. 불명확한 문제 설명, 올바른 답을 거부하는 테스트 같은 것들이죠. 이를 걸러내서 SWE-bench Verified(500개)가 만들어졌습니다.
- Terminal-Bench 2: 89개 task 중 31%가 커뮤니티와 저자의 수정 PR로 개선됐습니다. 부실한 테스트, 오해를 부르는 artifact, 환경 문제 등이었습니다.
- Terminal-Bench 1: 229개 task에 대해 108건의 커뮤니티 수정 PR이 접수됐습니다(2026년 5월 기준).
이런 결함이 사라지지 않는 이유는 노력이 부족해서가 아니라 수동 감사로는 규모를 감당할 수 없기 때문입니다. 게다가 모델이 강해질수록 새로운 결함이 드러납니다. frontier 모델이 SWE-bench Verified를 포화시킨 뒤 남은 실패 사례를 감사했더니, 그중 59%가 모델 한계가 아니라 테스트 결함 때문이었습니다.
Task Verification Bench
Task Verification Bench(TVB)를 소개합니다. 벤치마크 버전 diff를 ground truth로 활용하는 meta-benchmark입니다. 저자가 v2를 내놓으면, 수정된 각 task는 암묵적으로 “v1에서 결함이 있었다”고 표시하는 셈이 됩니다.
세 개의 벤치마크 계보에서 라벨을 모았습니다.
- SWE-bench: annotator 3명 감사에서 나온 결함 task 1,160개 (필터링 후 결함 129개 + 정상 129개 = 258개)
- Terminal-Bench 2: 결함 26개 + 정상 26개 = 52개
- Terminal-Bench 1: 결함 65개 + 정상 56개 = 121개 (GT 노이즈 필터링 후)

원본 task artifact(문제 설명, 테스트, 정답 패치)만 주어진 상태에서, LLM 에이전트는 각 task에 결함이 있는지 판정하고 올바른 원인까지 짚어내야 합니다.
Root-Cause Matching
핵심 설계는 하나입니다. 단순 탐지가 아니라 원인 매칭으로 평가한다는 것입니다.
에이전트가 task에 결함이 있다고 판정해도 이유가 틀리면 그 진단으로는 고칠 수 없습니다. 그래서 에이전트가 지적한 결함이 GT annotation과 맞아떨어져야 합니다. LLM judge가 에이전트의 분석과 GT를 비교하면서 던지는 핵심 질문은 이겁니다. 에이전트가 지적한 결함을 고치면 GT의 결함도 같이 해결되는가?
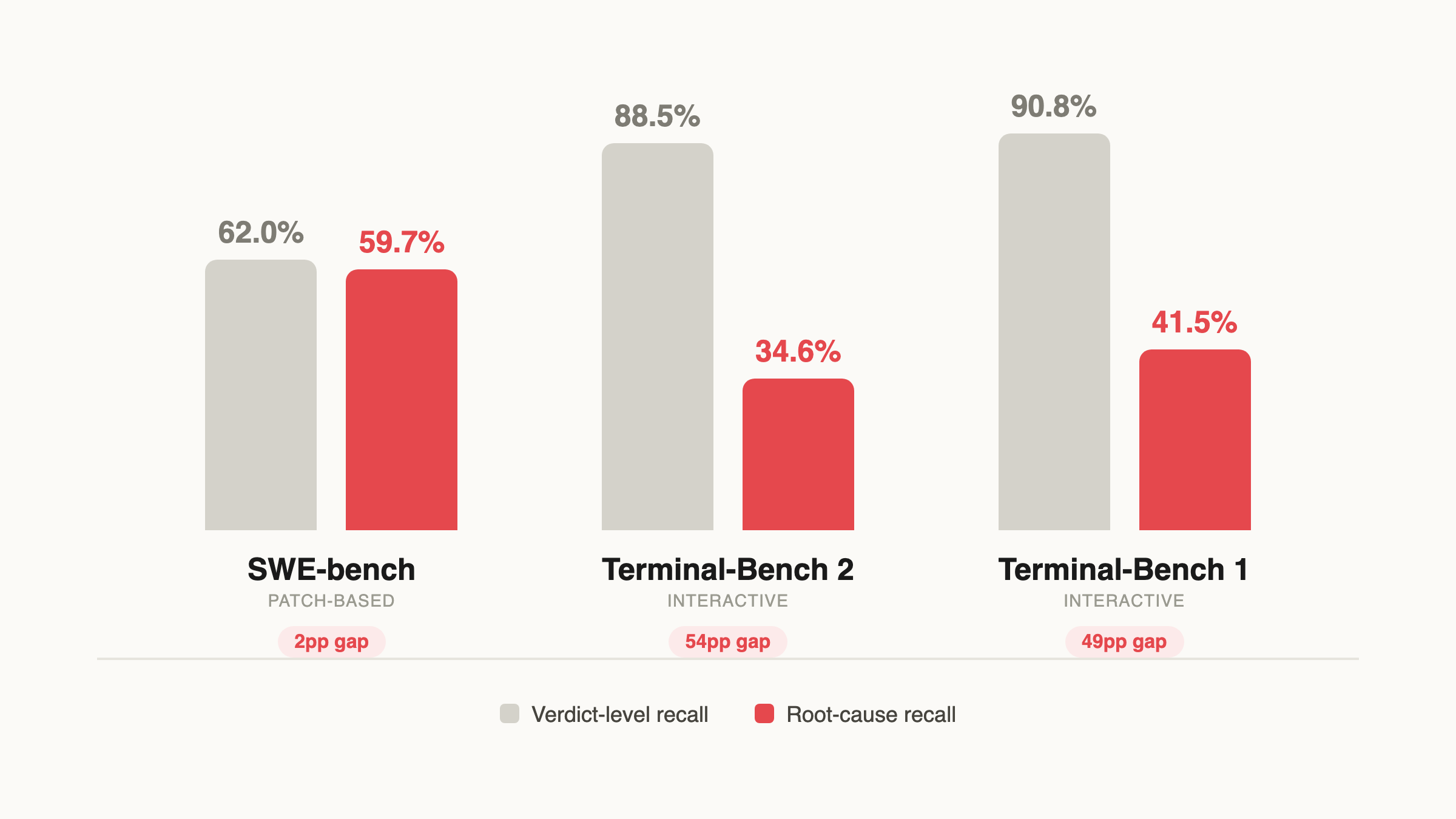
이 구분이 정말 중요합니다. 단순 판정 recall은 실제 탐지율을 최대 54 퍼센트포인트까지 부풀립니다.
주요 결과
벤치마크별 기본 성능 (GPT-5.4, verify-only + sandbox)
| SWE-bench | TB2 | TB1 | |
|---|---|---|---|
| 판정 Recall | 62.0% | 88.5% | 90.8% |
| 원인 매칭 Recall | 59.7% | 34.6% | 41.5% |
| 판정→원인 격차 | 2pp | 54pp | 49pp |
원인 매칭 recall은 35~60% 수준입니다. 사전 분류(triage)에는 쓸 만하지만, 완전 자동 감사에는 아직 부족합니다.
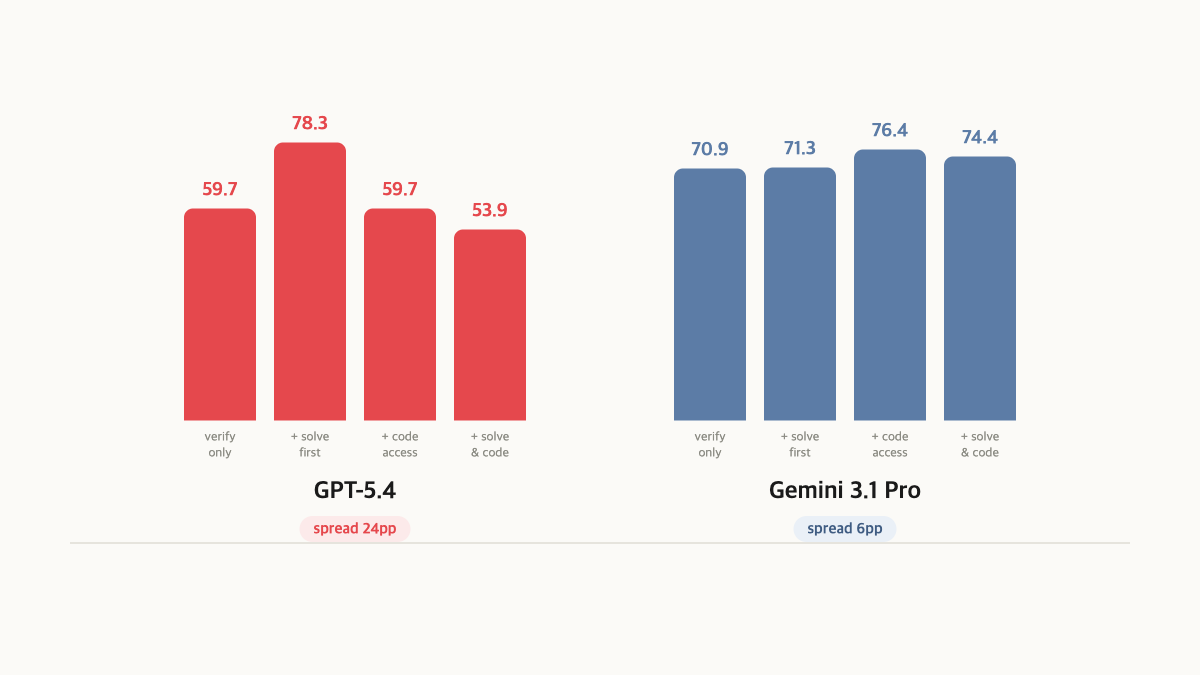
Self-Attribution Anchoring
SWE-bench에서 파이프라인 ablation을 돌리다가 흥미로운 현상을 발견했습니다. GPT-5.4가 task를 풀고 나서 자기 코드에 sandbox로 접근할 수 있는 상태로 검증하면, 벤치마크 탓이 아니라 자기 코드 탓으로 돌립니다. 그 결과 원인 매칭 recall이 78.3%에서 53.9%로 떨어졌습니다.
이를 self-attribution anchoring이라 부릅니다. 에이전트가 자기 실패 패치를 검토하다가, 테스트 실패를 자기 구현 탓으로 돌리고 원래라면 지적했을 결함을 그냥 넘겨버리는 거죠.
반면 Gemini 3.1 Pro는 이 효과를 거의 받지 않아, 모든 조건에서 원인 매칭 recall을 70~76%로 안정적으로 유지했습니다. 파이프라인 설계보다 모델 선택이 더 중요합니다.
텍스트 레이어 vs 인프라 레이어
에이전트는 텍스트 레이어 결함에는 강합니다. 문제 설명과 테스트 assertion을 비교해 불일치를 잘 찾아냅니다. 하지만 인프라 레이어는 사각지대입니다. 환경 문제, Dockerfile 유출, oracle 회귀 같은 건 더 긴 추론이 필요해서 에이전트가 번번이 놓칩니다.
샘플링한 정답 사례 6건은 모두 텍스트 레이어 결함이었고, Terminal-Bench의 오답·불일치 8건은 모두 인프라 레이어 결함이었습니다.
시사점
LLM을 활용한 감사는 텍스트 레이어 결함에서는 사람의 검토 부담을 크게 줄여 줍니다. 하지만 인프라 레이어 검증은 여전히 사람의 전문성이 필요한 영역입니다.
가장 좋은 워크플로우는 AI가 먼저 분류하고, 사람이 중요한 곳을 집중해서 보는 것입니다. LLM이 사람을 대체하는 게 아니라, 어디를 봐야 할지 짚어 주는 거죠.
이것이 바로 Delphik이 만들고 있는 것입니다.
논문 보기
“Can LLMs Detect Benchmark Defects? A Meta-Benchmark from Benchmark Version Diffs”
DL4C Workshop @ ICML 2026 채택.
Task Verification Bench 데이터셋과 평가 코드는 논문 게재 후 공개할 예정입니다.
저자 소개
박종원은 Delphik의 창업자로, AI 코딩 에이전트를 위한 eval infrastructure를 만들고 있습니다. 크래프톤(PUBG)에서 RL 연구 엔지니어로 일했고, 이후 300명 이상의 데이터 라벨러를 관리하는 AI 리드를 맡았습니다.