A benchmark with no reported defects isn’t clean. It’s unaudited.
Benchmark health isn’t a defect count. It’s whether discovery closes into a fix. Here’s that loop traced across 1,874 defect threads: what’s found, fixing, fixed, and still open.
There’s a trap in how people read benchmark quality: a repo with an empty issue tracker looks healthy, and a repo with a hundred open defect threads looks broken. It’s usually the other way around. The quiet benchmark is the one nobody has stress-tested; the noisy one is the one people run hard enough to find what’s wrong with it.
So “how many defects were reported” is the wrong health metric. A better one is a loop: how many defects get found, how many move into a fix, how many actually ship, and how much is still open. Health is whether discovery closes into a fix, not whether anyone complained.
We just published the people doing the finding: 744 public auditors across 62 agentic benchmark repos. This post is the other half: not who reports, but what happens after. We traced that loop across the same 1,874 defect threads (1,616 genuine on a full re-read), as a preview of what a benchmark’s health page should actually show.
Start with the benchmarks themselves. Ranked by how many defect threads each has drawn, the list reads less like the buggiest evals and more like the most stress-tested ones. The color is where each one’s defects sit in the loop, and it already shows closure is anything but uniform.
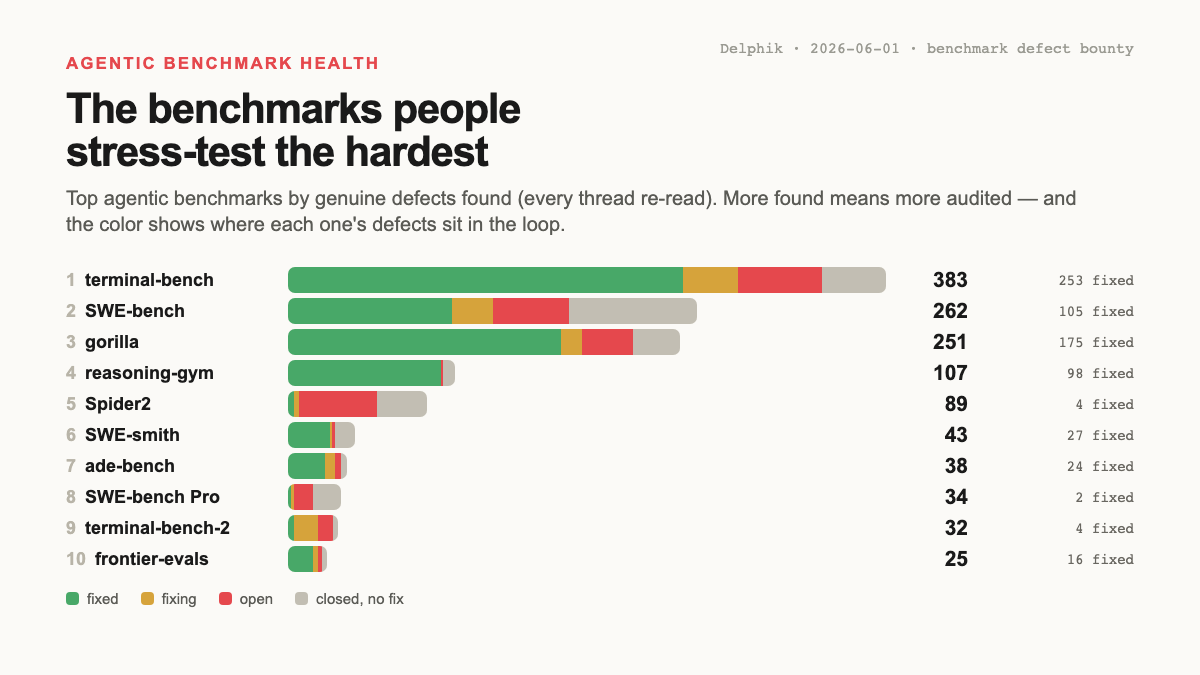
Same kind of surface, very different closure: reasoning-gym has a merged fix behind ~90% of what’s reported, while Spider2 has ~50 “wrong gold query/answer” reports still sitting open. A thick band of open reports means reported defects aren’t actually getting fixed, and that’s true whether a repo works in PRs, Issues, or direct commits (we read every commit to confirm Spider2’s open reports really are unresolved, not just unlinked). That’s what a health view is for: it tells a user how much of the known defect surface is actually retired in the version they’re about to run.
Found, fixing, fixed
Zoom out from individual repos to all 1,616 genuine defects at once, and most have moved through the loop:
- 315 are open: an Issue filed, no fix in flight yet.
- 132 are fixing: an open PR, a proposed fix in review.
- 817 are fixed, with merged-PR evidence behind them (a merged fix PR, or an Issue closed by one).
- 352 are closed with no merged PR: out of the loop.

The first three are the loop: found → fixing → fixed. The big green bar is the real story: most defects that get reported do get fixed.
The fourth bucket is where we’re deliberately conservative. Those 352 closed without a merged PR aren’t evidence of a fix, but they’re not all noise either: won’t-fix, duplicate, fixed by a commit nobody linked, or the occasional report that didn’t hold up. “Closed” simply isn’t “fixed,” which is the whole reason a health surface has to track merge evidence, not GitHub state.
Fixing is continuous, not a launch-day spike
You might expect defects to cluster right after release and then taper. They cluster, but they don’t taper.

882 (62%) surfaced in the first year, but 547 (38%) surfaced after year one, and the last 90 days alone produced ~137. Benchmarks keep generating defects long after launch, partly because stronger agents keep probing them in new ways, partly because the stack underneath drifts: a base image updates, a dependency pin goes stale, an external API changes, and a task that used to reproduce no longer does. Keeping a benchmark healthy is an ongoing job, which is the whole reason a one-time audit, however good, can’t be the end of it. BenchJack (Wang et al., 2026) shows a version of this experimentally on the exploit side: patching a benchmark’s loopholes in a single round often isn’t enough: re-auditing drives the hack rate back up, and a couple of benchmarks needed several iterations to fully close (§5.3, Fig. 7).
Static benchmarks have bugs too. The difference is the evidence surface
Static benchmarks aren’t clean either: we re-read every Issue/PR across 10 well-known static ones and found genuine defects in each: wrong gold answers, duplicate labels, ambiguous questions, scoring bugs. But per task they’re far less dense. Take the top 10 benchmarks by GitHub stars in each class (by popularity, not by defect count), divide each one’s defect threads by its real task count, and agentic benchmarks average about 266 defects per 1,000 tasks against 57 for static, roughly 4.6× on re-verified genuine defects (median benchmark ~7×).
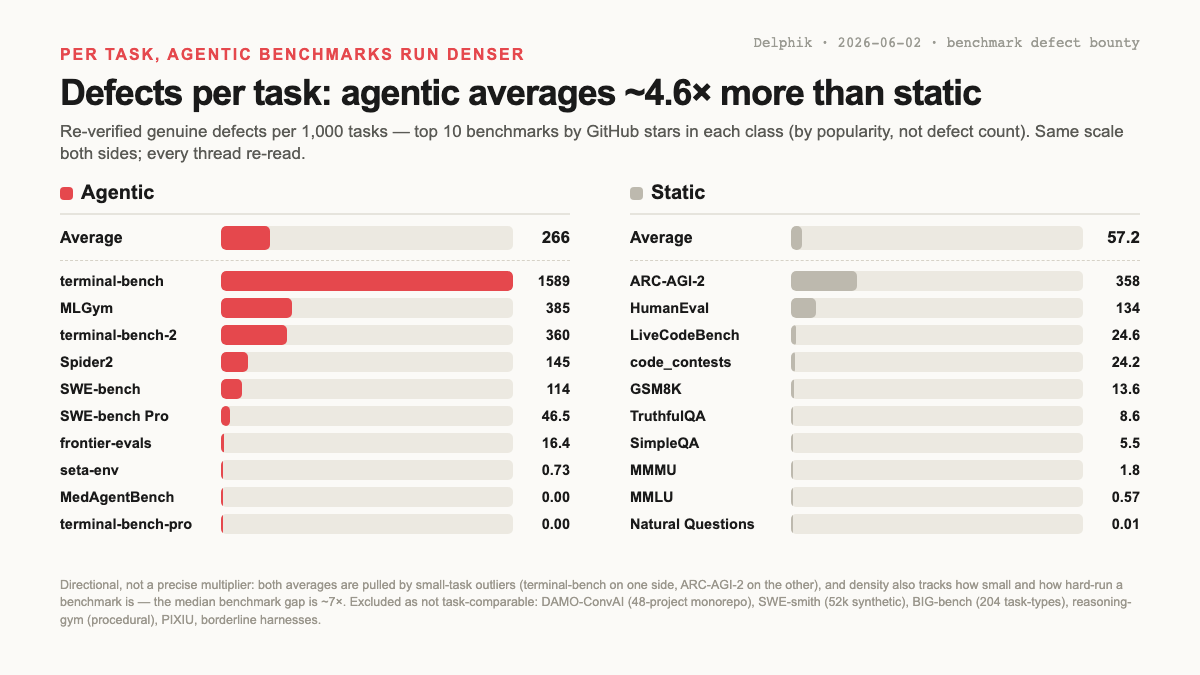
It’s directional, not a precise multiplier. Both averages are pulled by small, hard-run outliers (terminal-bench on the agentic side, ARC-AGI-2 on the static), and density tracks how small and how heavily-run a benchmark is as much as how buggy it is, which is why a few small static code and reasoning sets run dense too. The point isn’t that static benchmarks are fine; it’s that agentic benchmarks give a defect more places to live (task setup, tools and APIs, the environment, the harness, verifier/oracle logic, the trajectory itself), and all of it lands on the score. That’s why benchmark health has to be a loop, capture → triage → fix → versioned-fixed, not an errata page.
Where Defect Hub fits
Everything in this post lived in GitHub Issues and PRs, which is right for the discussion and the patch, and should stay there. But GitHub holds the conversation and the merge; it doesn’t hold the benchmark. It’s the same split that put model weights on Hugging Face instead of a plain Git repo: Git is right for the code, wrong for the artifact around it. A benchmark defect is that artifact. It has a task, a version, a run trajectory, and an effect on the score, and an Issue can’t carry any of them. So three things fall through, and they’re what Defect Hub is for.
One defect, one managed thread, instead of a pile of open Issues. Right now the evidence scatters: Spider2’s ~50 open “wrong gold” reports include the same defect filed more than once, none tied to a run or to the version it breaks. Elsewhere the reverse happens, a defect fixed by a direct commit that never closes its Issue, so it still reads as open. Either way, GitHub’s open/closed state isn’t the truth. Defect Hub makes a defect a single object instead, captured from inside your coding agent in one /report-defect with the run trajectory attached, then deduped, routed to the maintainer, and tracked through the real fix and the versioned re-release. Found → fixing → fixed, not a backlog nobody is closing. This shipped last week.
A public health record maintainers can actually stand behind. The found → fixing → fixed loop, per benchmark, gives users evidence that the benchmark is actively maintained instead of asserting it.It ships this week.
A leaderboard that moves when the benchmark is fixed. Fixing defects changes the scores: Terminal-Bench fixed 28 of its 89 tasks and the top agent jumped about 12 points while the ranking largely held (writeup). A frontier number measured once on the buggy version and frozen doesn’t survive that. But a fix only touches a handful of tasks, so the leaderboard doesn’t need a full re-run, just the fixed tasks re-scored for each model. That’s how a score stays tied to the current version instead of frozen on the bugs it shipped with. It ships next week.
One honest caveat: raw counts aren’t a health score. The real metric normalizes by task count and adoption (stars, clones, runs), because an unaudited benchmark looks clean only because nobody has hit its defects yet; that’s next, not a claim we’re making today. The 744 people already doing this work are why these benchmarks hold up; our job is to make the next report cheaper than the last. If you hit a broken eval task, reporting it should be one command.
Methodology & caveats
Snapshot of 6,245 parent GitHub Issue/PR threads across 62 agentic benchmark repos on 2026-06-01; 1,874 flagged as defect-like, of which 1,616 are genuine defects on a full re-read (see the re-read note below). How we found and classified those defects, how the threads were read (by coding agents, not keyword-matching), scored, and split between public auditors and repo teams, is detailed in the companion post. This post picks up after classification, and groups the 1,616 genuine defects by where they sit in the loop:
- fixed (817): merged-PR evidence, a PR that merged, or an Issue closed by a linked merged PR.
- fixing (132): an open PR, a proposed fix in review.
- open (315): an open Issue with no merged outcome yet.
- closed (352): closed with no merged PR.
As a check on the “open” counts: because some repos fix defects via direct commits rather than linked PRs, we didn’t trust the merged-PR signal alone. We read all 7,722 commits across the 36 repos (with subagents) and tested every still-open defect for a commit that actually resolved it, confirmed by reading the diff, not keyword matching. Only ~5% had been silently fixed this way, so the open figures here are real, not an artifact of commit-based fixing.
Other notes:
- Every count here is genuine defects (re-read, independently). After a maintainer flagged an ambiguous count, we re-read every one of the 1,874 flagged threads in full (bodies and diffs, not titles, on both the agentic and static sides) and had a different model re-classify them independently. 1,616 are genuine benchmark defects (~86%; between 80% strict and 96% inclusive depending on how borderline cases are counted); the rest are repo construction (language ports, CI, test scaffolding) our first-pass classifier over-included, concentrated in a few older repos (QuixBugs, for instance, was 14 of 42, and it and other static repos are excluded). Every figure in this post is the genuine count. The per-task gap barely moves either way, ~4.6× genuine vs ~4.8× flagged, because the over-count was roughly proportional.
- This is a sample, not a census. Every number in this post comes from the benchmarks we’ve actually audited, a seed set of agentic benchmarks from our Harbor index plus a separate hand-picked set of well-known static ones, not from every benchmark that exists. So “top 10 by stars” means the 10 most-starred within that set; more popular benchmarks we haven’t indexed yet sit outside it and would shift the leaderboard, the counts, and the averages. Read everything here as a read on the benchmarks we cover, which we’re expanding.
- The counting unit is the parent Issue/PR thread, not individual comments.
- “Fixing” is approximated as open PRs. We count at the thread level, so a reported Issue and its in-flight PR show up as one open and one fixing; we don’t have reliable Issue→open-PR linkage to merge them.
- Task-normalized comparison. We took the top 10 benchmarks by GitHub stars in each class (chosen on popularity, not defect count, so the sample isn’t picked on what we’re measuring) and read each one’s task count from its repo and paper (one gradeable item = one task). The ~4.6× is directional: both averages lean on one small-task outlier each (terminal-bench; ARC-AGI-2), and dropping either leaves the gap still a few× in the same direction. Excluded from the per-task chart as not task-comparable: a 48-project monorepo (DAMO-ConvAI), a 52k synthetic set (SWE-smith), a procedural generator (reasoning-gym), BIG-bench (204 task-types), and a few single-shot-with-execution harnesses on the boundary.
- Launch timing is GitHub repo
created_at, which can differ from paper or official release dates; read the time axis as “activity since the repo went public.” - External figures referenced elsewhere in this series (the SWE-bench Verified re-audit, the DeepSWE/SWE-bench Pro check) are from those teams’ public reports, not our dataset.
