The unsung heroes fixing agentic benchmarks
We read 6,245 GitHub threads across 62 benchmark repos to find the 744 people quietly keeping these benchmarks in working order. This is a shoutout to them, and the data behind it.
We've spent a fair number of words on what's wrong with coding benchmarks: verifiers that reject correct code, leaked solutions, tasks no agent could ever pass. We've also written about whether a model could just audit them for us. (Short version: it helps with triage, but it can't replace a person. We wrote that up here.)
This post is about a question we'd argued about but never actually measured: who is actually keeping these benchmarks in working order, and why does it cost them so much?
Because someone clearly is. The best benchmarks are actively maintained. SWE-bench and Terminal-Bench ship fixes as defects surface, and yet the defects keep coming, so the maintenance never really stops. That work is real, it happens mostly out in the open on GitHub, and a lot of it is not done by the people whose names are on the paper. So we stopped guessing and counted.
Across 62 agentic benchmark repos we read 6,245 parent Issue and PR threads, classified 1,874 of them as benchmark defects or probable defects, and traced 744 public auditors behind them: people not on any maintainer roster who filed an Issue, opened a fix PR, or both.
This is a shoutout to them.
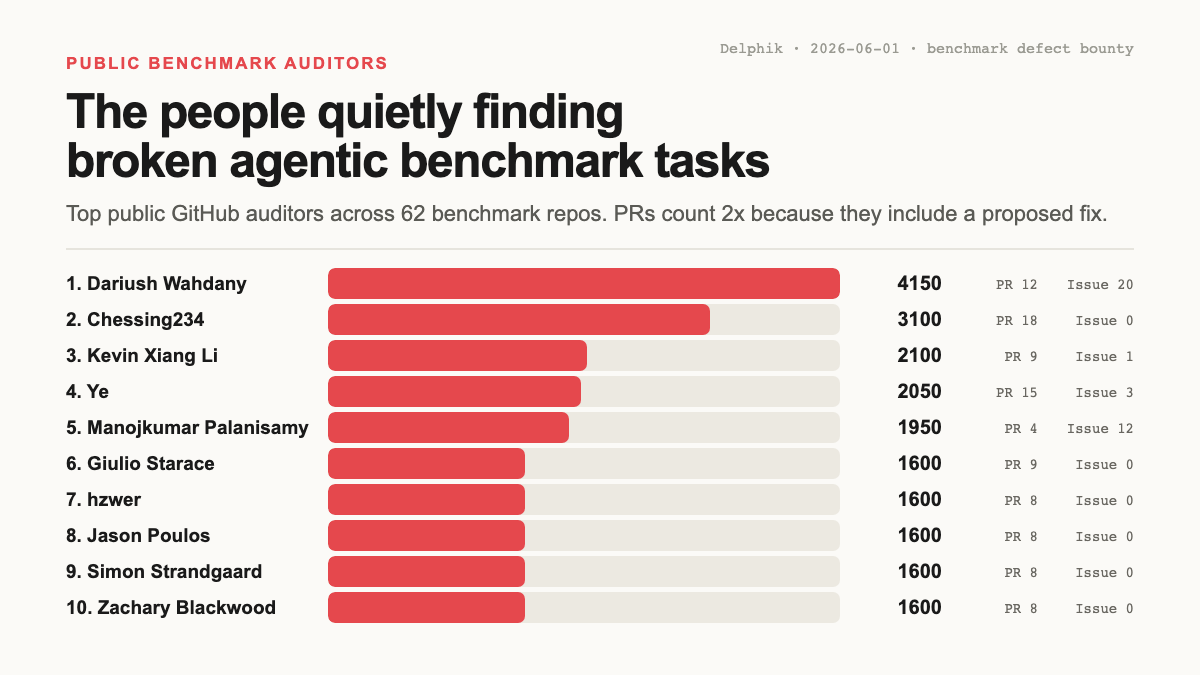
The discovery is mostly coming from outside the repo
We split everyone into public auditors (GitHub author association not OWNER, MEMBER, or COLLABORATOR) and repo-team authors, to see who does what.
| segment | defect threads | PR | Issue | resolved |
|---|---|---|---|---|
| public auditors | 1,290 | 574 | 716 | 487 |
| repo-team authors | 583 | 440 | 143 | 462 |
Public auditors filed about 2.2× as many defect threads as the repo teams overall, but the gap is lopsided once you split by type. On Issues (a “this is broken” report) it's 716 vs 143, roughly 5×; on PRs (an actual attempted fix) it's only 574 vs 440, about 1.3×. In other words, public auditors out-report the repo teams far more than they out-fix them: the people outside the project find most of what gets reported.
Repo teams, in turn, do most of the closing. They merge a higher share of PRs and resolve more of what crosses their desk. Which is exactly as it should be; closure usually has to happen inside the project, by whoever holds the commit bit and the context.
So this isn't auditors versus maintainers. It's a division of labor that already works: outsiders widen the surface that gets checked, the team lands the fixes, and the benchmark gets a little better each pass. The constraint isn't a shortage of people willing to do this. It's that everything around a single fix is scattered, which, as we'll get to, is what makes each report cost more than it should.
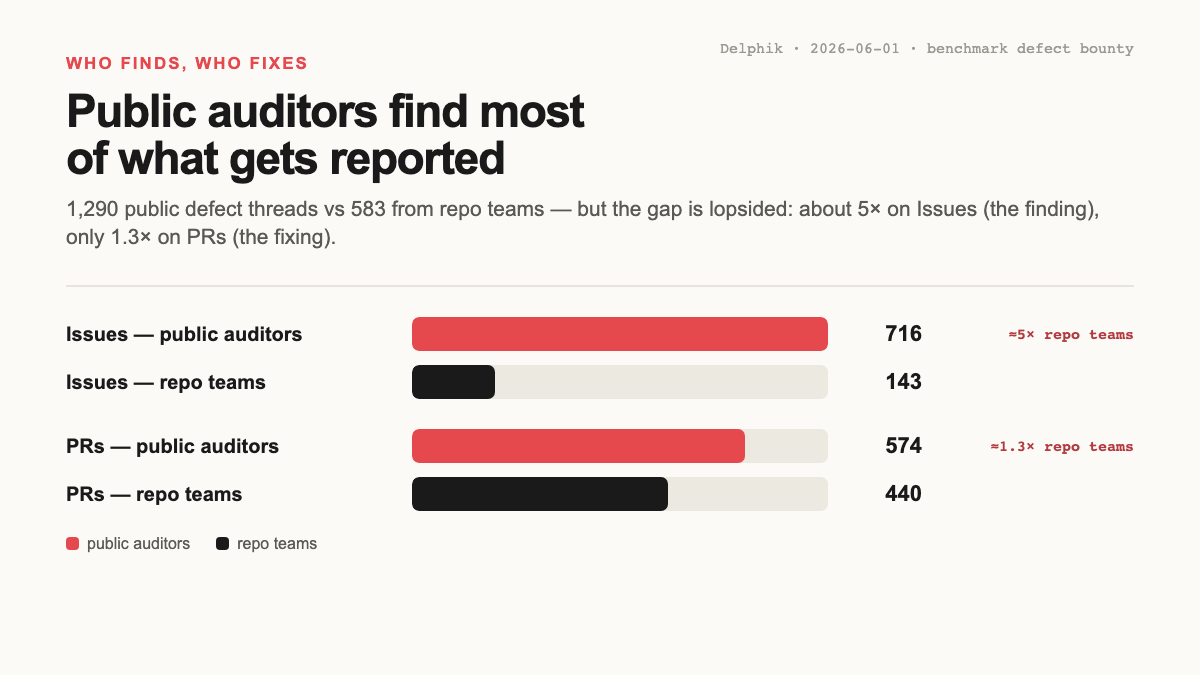
The top 10
| # | auditor | score | defects | PR | Issue | contact |
|---|---|---|---|---|---|---|
| 1 | Dariush Wahdany | 4,150 | 32 | 12 | 20 | @dwahdany |
| 2 | Chessing234 | 3,100 | 18 | 18 | 0 | GitHub |
| 3 | Kevin Xiang Li | 2,100 | 10 | 9 | 1 | @kevin_x_li |
| 4 | Ye | 2,050 | 18 | 15 | 3 | heye.me |
| 5 | Manojkumar Palanisamy | 1,950 | 16 | 4 | 12 | @smartmanoj42857 |
| 6 | Giulio Starace | 1,600 | 9 | 9 | 0 | @thelokasiffers |
| 7 | hzwer | 1,600 | 8 | 8 | 0 | @hzwer |
| 8 | Jason Poulos | 1,600 | 8 | 8 | 0 | poulos.ai |
| 9 | Simon Strandgaard | 1,600 | 8 | 8 | 0 | @SimonStran36407 |
| 10 | Zachary Blackwood | 1,600 | 8 | 8 | 0 | @blackaryz |
The score weights a PR at 2× an Issue, because a PR carries a repair someone actually attempted, not just a flag. There's a small bonus for working across multiple benchmarks, capped so breadth can't drown out depth. And it deliberately ignores merge status (an unmerged PR against a quiet repo is still someone doing the work), so whether the fix landed is tracked separately, not baked into the ranking. Full formula at the bottom.
The names map cleanly onto the benchmarks that are live right now: terminal-bench and its v2, the SWE-bench family, ARC-AGI-2, ade-bench, frontier-evals. Some are clearly regulars in their corner; others showed up once, hit something real, and wrote it up well. Both belong here.
Couldn't a model just do this now?
It's the obvious follow-up, with 744 people doing this by hand, so we tested it directly and wrote up the result on its own (here). The part that matters for this post: an LLM auditor will flag almost any broken task, but on the defects that matter most, the infrastructural ones, a drifting image or a leaked solution rather than a prompt that disagrees with its own test, it names the wrong cause more often than not, even handed the full environment. It tends to blame its own attempt before it blames the benchmark.
The layer that's hardest to diagnose is the one a standalone auditor handles worst and a person running the eval handles best, because they were there when it broke, with the trajectory still in front of them. The 744 people on this list aren't keeping a seat warm until automation arrives. They're doing the part that doesn't automate.
Why it costs them more than it should
The friction isn't the diagnosis. It's everything around it. A single benchmark defect ends up scattered across half a dozen places: the trajectory where it first surfaced, a local note, a GitHub Issue, a follow-up PR, a maintainer's reply, and eventually, if you're lucky, a release that actually contains the fix. The GitHub patch loop is the one piece of that with good tooling. The benchmark-specific thread tying it together (which task, which version, which run triggered it, whether the fix reached the version people actually run) never lives in one place.
That's most of the reason the people above had to work as hard as they did. A good benchmark defect report isn't just an Issue. It's re-running the eval to be sure it's the task and not your own agent, trimming the trajectory down to something readable, finding the right repo among forks and registries, finding the right maintainer, writing it up, and then, weeks later, checking whether the fix shipped at all. Each step is small. Stacked up, they're enough that most people who hit a broken task quietly move on and report nothing.
And there's a cost on top of the individual one. Because none of this is tracked in one place, the same work gets redone: a defect one person diagnosed and reported in a fork or a Discord is invisible to the next team, who burns compute rediscovering it a quarter later. The maintenance is happening, it's just not pooled, so the field keeps paying for the same fixes more than once.
Where Defect Hub fits
This is the gap Defect Hub is built for, and these 744 people are exactly who it's for. It doesn't move anything off GitHub: the merge and the conversation stay with the maintainers. It just holds the benchmark-specific context together for the whole life of a defect: captured the moment the agent hits it, trajectory attached, pinned to the task and version, routed to the right maintainer, and tracked until the fix actually ships. The full mechanics are in the launch post. It's aiming at two things: that filing a defect takes a little less effort each time, and that once a defect is verified and fixed it stays as an open record the whole field can cite, instead of the next team burning compute to rediscover it.
We wrote this before pitching any of that, on purpose. The work we want to support is already happening, and the 744 names in this dataset are a big part of why agentic benchmarks hold up at all. If you're one of them: thank you. If you know one: send them this.
Methodology
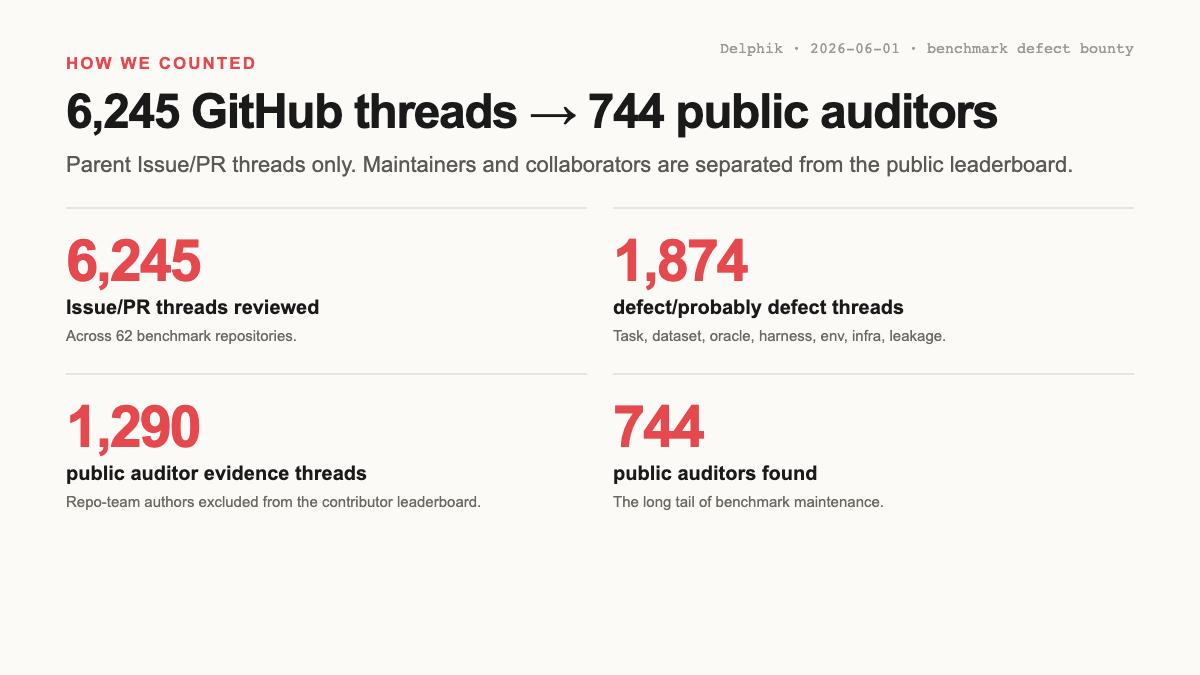
We reviewed 6,245 parent GitHub Issue/PR threads across 62 agentic benchmark repos, snapshotted on 2026-06-01.
- 1,874 threads classified as defect or probable defect.
- 1,290 by public auditors (574 PR / 716 Issue), from 744 unique people.
- 583 by repo-team authors (440 PR / 143 Issue), kept as benchmark health signal, excluded from the public-auditor leaderboard.
Score:
evidence_score = 200 * defect_PR
+ 100 * defect_Issue
+ 100 * probably_defect_PR
+ 50 * probably_defect_Issue
leaderboard_score = evidence_score + repo_diversity_bonus
repo_diversity_bonus = +200 per extra benchmark repo, max +600Caveats:
- The counting unit is the parent Issue/PR thread, not individual comments.
- Repo-team authors are separated by GitHub author association (
OWNER,MEMBER,COLLABORATOR); bots are excluded from the leaderboard too. - PR score is independent of merge status. A merged PR closes the loop; an unmerged one is still evidence someone tried.
- A closed thread isn't automatically counted as fixed. Closed-unmerged PRs and Issues closed without a linked merged PR sit in a separate resolution-gap bucket.
- This is a public GitHub surface audit as of 2026-06-01, not an all-time claim about every benchmark defect ever filed.
If we missed someone, and across 744 names we almost certainly did, tell us and we'll add them.
