Defect 보고가 0인 benchmark는 깨끗한 게 아닙니다. Audit이 안 된 겁니다.
Benchmark health는 defect 개수가 아니라, 발견이 fix로 닫히느냐입니다. defect thread 1,874개에 대해 그 loop를 추적했습니다. 무엇이 found·fixing·fixed이고, 무엇이 아직 열려 있는지.
benchmark 품질을 읽을 때 빠지기 쉬운 함정이 있습니다. issue tracker가 텅 빈 repo는 건강해 보이고, open defect thread가 100개 쌓인 repo는 망가져 보입니다. 보통은 반대입니다. 조용한 benchmark는 아무도 세게 굴려보지 않은 것이고, 시끄러운 benchmark는 사람들이 충분히 세게 굴려서 뭐가 잘못됐는지 실제로 찾아낸 것입니다.
그래서 “defect가 몇 개 보고됐나”는 잘못된 health 지표입니다. 더 나은 건 loop입니다: defect가 얼마나 발견되고, 얼마나 fix로 넘어가고, 얼마나 실제로 ship되고, 얼마가 아직 열려 있는가. Health는 누가 불평했느냐가 아니라, 발견이 fix로 닫히느냐입니다.
발견하는 사람들은 방금 따로 다뤘습니다. 62개 agentic benchmark repo의 public auditor 744명입니다. 이 글은 나머지 절반, 즉 누가 보고하느냐가 아니라 그 다음에 무슨 일이 일어나느냐입니다. 같은 defect thread 1,874개(전수 재독 결과 genuine 1,616개)에 대해 그 loop를 추적했습니다. benchmark의 health page가 실제로 보여줘야 할 것의 preview로요.
벤치마크 자체부터 봅시다. 각자가 끌어모은 defect thread 수로 줄세우면, 이 목록은 “가장 buggy한 eval”이라기보다 “가장 많이 stress-test된 eval”에 가깝게 읽힙니다. 색은 각 defect가 loop 상 어디 있는지이고, 이미 closure가 결코 균일하지 않다는 걸 보여줍니다.
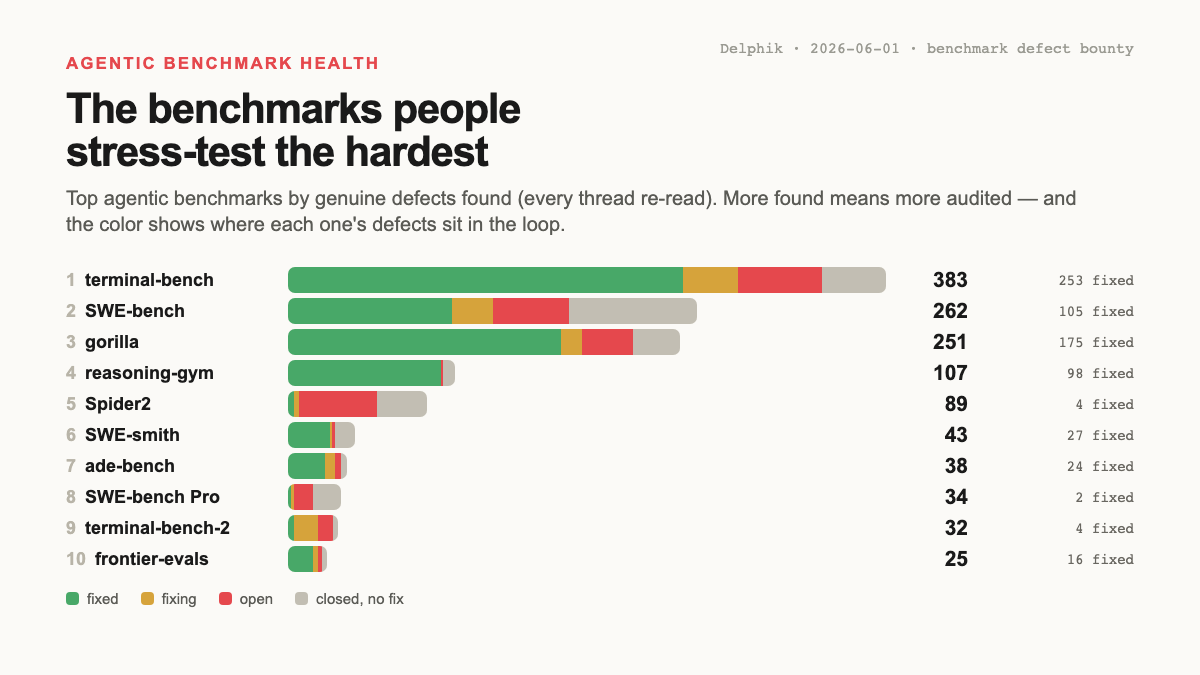
같은 종류의 surface인데 closure는 repo마다 천차만별입니다: reasoning-gym은 보고된 것의 ~90%에 merged fix가 있는 반면, Spider2는 “gold query/answer가 틀렸다”는 신고 ~50개가 아직 열린 채 쌓여 있습니다. open이 두껍다는 건 보고된 defect가 실제로 안 고쳐지고 있다는 뜻입니다. PR로 받든, Issue로 받든, commit으로 고치든 마찬가지로요 (Spider2의 open 신고가 단지 link만 안 된 게 아니라 정말 안 고쳐진 건지, commit을 다 읽어 확인했습니다). 이게 바로 health view가 하는 일입니다. 지금 돌리려는 그 version에서 알려진 defect surface가 얼마나 실제로 정리됐는지를 사용자에게 말해주니까요.
Found, fixing, fixed
개별 repo에서 1,616개 genuine defect 전체로 줌아웃하면, 대부분은 loop를 통과해 움직였습니다:
- 315개는 open: Issue는 올라왔지만 아직 fix가 진행 중이지 않음.
- 132개는 fixing: open PR, 즉 review 중인 제안된 fix.
- 817개는 fixed: merged PR로 뒷받침됨 (merge된 fix PR, 또는 그런 PR로 닫힌 Issue).
- 352개는 merged PR 없이 closed: loop 바깥.

앞의 셋이 loop입니다: found → fixing → fixed. 큰 초록 막대가 진짜 핵심입니다. 보고된 defect의 대부분은 결국 fix됩니다.
네 번째 bucket에서만 우리는 의도적으로 보수적입니다. merged PR 없이 닫힌 352개는 fix의 증거가 아니지만, 그렇다고 다 noise인 것도 아닙니다: won’t-fix, duplicate, link 안 한 commit으로 이미 fix, 그리고 가끔 끝내 성립 안 한 report. “closed”는 “fixed”가 아니고, 그래서 health surface가 GitHub state가 아니라 merge evidence를 추적해야 하는 것입니다.
수정은 launch 당일 spike가 아니라 계속됩니다
defect가 release 직후 몰렸다가 잦아들 거라 예상하기 쉽습니다. 몰리긴 하는데, 잦아들지 않습니다.

882개(62%)는 첫 1년에 나왔지만, 547개(38%)는 1년 이후에 나왔고, 최근 90일에만 ~137개가 나왔습니다. Benchmark는 launch 한참 뒤에도 계속 defect를 만들어냅니다. 더 강한 agent가 새로운 방식으로 계속 찔러보기도 하고, 그 아래 깔린 환경이 변하기도 하니까요: base image가 업데이트되고, dependency pin이 stale해지고, 외부 API가 바뀌면서, 한때 재현되던 task가 더는 재현되지 않습니다. Benchmark를 건강하게 유지하는 건 계속되는 일이고, 그게 한 번의 audit이 아무리 잘해도 끝이 될 수 없는 이유입니다. BenchJack(Wang et al., 2026)이 exploit 쪽에서 이걸 부분적으로 실험으로 보였습니다: 벤치마크 loophole을 한 번 patch하는 걸로는 부족할 때가 많아서, 다시 audit하면 hack rate가 도로 올라가고, 일부 벤치마크는 완전히 막는 데 여러 번 iteration이 필요했습니다 (§5.3, Fig. 7).
Static benchmark도 버그가 있습니다. 차이는 evidence surface입니다
static benchmark도 깨끗하지 않습니다: 잘 알려진 static benchmark 10개의 Issue/PR을 다시 읽었더니 각 벤치에서 genuine defect가 나왔습니다: wrong gold answer, duplicate label, ambiguous question, scoring bug. 하지만 task당으로 보면 훨씬 덜 dense합니다. 각 class에서 GitHub star 상위 10개(defect 수가 아니라 인기 기준)를 잡고 각 benchmark의 defect thread를 실제 task 수로 나누면, agentic은 task 1,000개당 약 266개, static은 57개로, 재검증된 진짜 defect 기준 대략 4.6×입니다(중앙값 기준 약 7×).
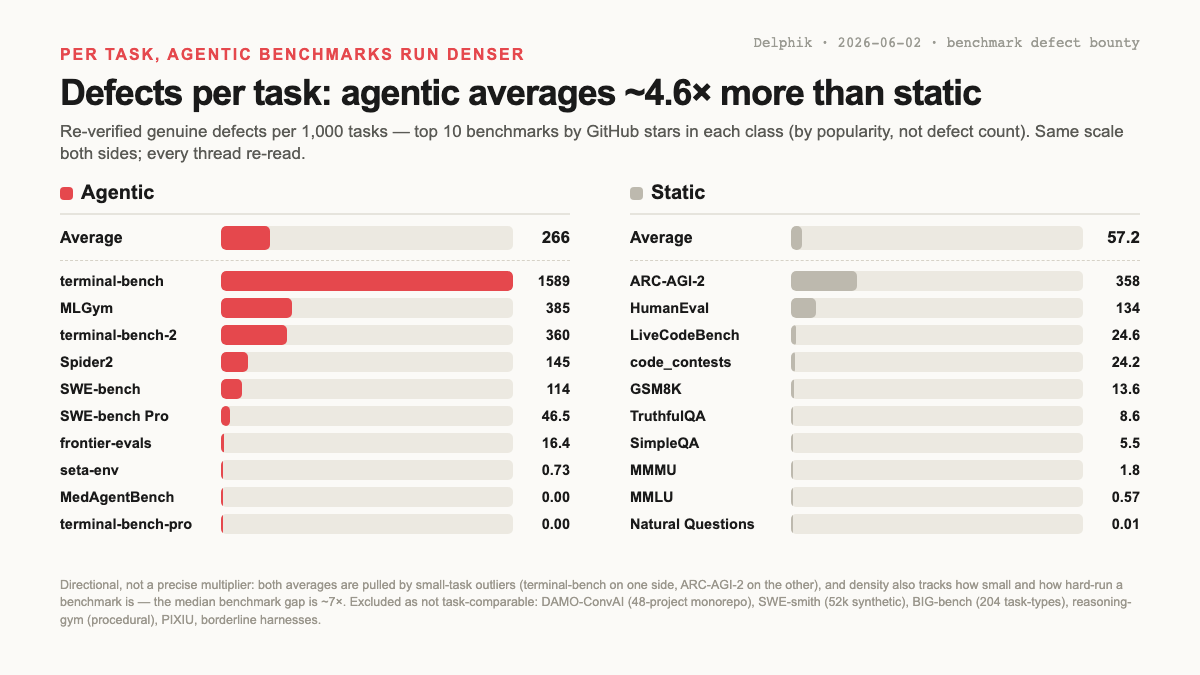
정확한 배수는 아니라 방향성입니다. 양쪽 평균 모두 task가 작고 빡세게 돌려지는 outlier 하나씩(agentic은 terminal-bench, static은 ARC-AGI-2)에 끌립니다. density는 benchmark가 얼마나 buggy한지만큼 얼마나 작고 많이 돌려지는지에도 좌우되고, 그래서 작은 static code·reasoning set 몇 개도 꽤 dense하게 나옵니다. 요지는 “static은 멀쩡하다”가 아닙니다. agentic benchmark는 defect가 살 수 있는 곳(task setup, tool·API, environment, harness, verifier/oracle logic, trajectory 자체)이 더 많다는 것이고, 그게 전부 score로 떨어집니다. 그래서 benchmark health는 errata page가 아니라 loop, 즉 capture → triage → fix → versioned-fixed여야 합니다.
Defect Hub는 어디에 들어가나
이 글의 모든 게 GitHub Issue·PR에 있었습니다. 논의와 patch는 거기 있어야 맞습니다. 하지만 GitHub는 대화와 merge는 담아도, benchmark는 담지 못합니다. model weight가 plain Git repo가 아니라 Hugging Face로 간 것과 같은 분기입니다: Git은 코드엔 맞고, 그 둘레의 artifact엔 안 맞습니다. benchmark defect가 바로 그 artifact입니다. task, version, run trajectory, 그리고 점수에 주는 영향을 갖는데, Issue는 그 어느 것도 담지 못합니다. 그래서 세 가지가 새어나가고, 그게 Defect Hub가 하는 일입니다.
defect 하나 = 관리되는 thread 하나. 안 닫히는 open Issue 더미가 아니라. 지금은 근거가 흩어집니다: Spider2의 open “wrong gold” 신고 ~50개엔 같은 defect를 두 번 올린 것도 있고, 어느 것도 run이나 그게 깨뜨리는 version에 안 묶여 있습니다. 반대로, defect를 직접 commit으로 고쳤는데 Issue를 안 닫아 여전히 열린 것처럼 보이는 경우도 있죠. 어느 쪽이든 GitHub의 open/closed 상태가 곧 진실은 아닙니다. Defect Hub는 defect를 단일 object로 만듭니다. coding agent 안에서 /report-defect 한 줄로 run trajectory와 함께 capture하고, dedup → maintainer로 route → 실제 fix와 versioned 재배포까지 추적. found → fixing → fixed, 아무도 안 닫는 backlog가 아니라. 지난주에 공개했습니다.
maintainer가 실제로 내세울 수 있는 공개 health record. found → fixing → fixed loop를 benchmark별로 보여줘서, maintainer가 자기 benchmark가 적극 관리되고 있다는 걸 주장이 아니라 증명으로 보여줍니다.이번 주에 공개됩니다.
benchmark가 고쳐지면 같이 움직이는 leaderboard. defect를 고치면 점수가 바뀝니다. Terminal-Bench는 89개 task 중 28개를 고쳐서 최상위 agent가 ranking은 대체로 유지된 채 약 12점 뛰었습니다(writeup). 버그 있던 version에서 한 번 재고 고정한 frontier 점수는 이걸 못 버팁니다. 그런데 fix는 task 몇 개만 건드리니까, benchmark 전체를 다시 돌릴 필요 없이 고쳐진 task만 모델별로 다시 채점하면 됩니다. 그래야 점수가 버그 박힌 version에 고정되는 대신 현재 version에 묶여 있게 됩니다. 다음 주에 공개됩니다.
솔직한 caveat 하나: raw count는 health score가 아닙니다. 진짜 지표는 task 수와 adoption(star, clone, run)으로 정규화해야 합니다. audit 안 된 benchmark는 아무도 defect를 안 건드려서 깨끗해 보일 뿐이니까요. 그건 다음 작업입니다. 이미 이 일을 하고 있는 744명이 이 benchmark들을 버티게 하는 이유이고, 우리 일은 다음 report가 지난 report보다 덜 들게 만드는 것입니다. broken eval task를 만나면, 보고는 한 줄이어야 합니다.
Methodology & caveats
2026-06-01 기준, 62개 agentic benchmark repo의 parent GitHub Issue/PR thread 6,245개 snapshot; 1,874개를 defect-like로 flag했고, 전수 재독 결과 1,616개가 genuine defect입니다(아래 재검토 노트). 이 defect들을 어떻게 찾고 분류했는지, 즉 thread를 어떻게 읽고(keyword match가 아니라 coding agent가 직접), 점수 매기고, public auditor와 repo team으로 나눴는지는 companion post에 정리돼 있습니다. 이 글은 분류 이후를 다루며, 1,616개 genuine defect를 loop상의 위치로 묶습니다. loop bucket:
- fixed (817): merged-PR evidence, merge된 PR, 또는 linked merged PR로 닫힌 Issue.
- fixing (132): open PR, review 중인 제안된 fix.
- open (315): 아직 merged 결과가 없는 open Issue.
- closed (352): merged PR 없이 닫힘.
“open” 수치 검증: 일부 repo는 linked PR이 아니라 직접 commit으로 defect를 고치기 때문에, merged-PR 신호만 믿지 않았습니다. 36개 repo의 commit 7,722개를 전부 (subagent로) 읽고, 아직 open인 defect마다 실제로 그걸 고친 commit이 있는지 keyword가 아니라 diff를 읽어 확인했습니다. 그렇게 조용히 고쳐진 건 ~5%뿐이라, 여기 open 숫자는 commit-기반 fixing 때문에 부풀려진 게 아니라 실제 값입니다.
기타:
- 이 글의 모든 수치는 genuine defect (독립 재검토). 한 maintainer가 카운트의 모호함을 지적한 뒤, flag된 1,874개 thread를 제목이 아니라 본문·diff까지(agentic·static 양쪽 다) 전부 다시 읽었고, 별도의 다른 모델로 독립 재분류까지 돌렸습니다. 1,616개가 genuine benchmark defect입니다(~86%; 경계 케이스를 얼마나 엄격히 세느냐에 따라 80% strict ~ 96% inclusive). 나머지는 우리 1차 분류기가 결함으로 잘못 포함한 repo 구축 작업(언어 포팅, CI, 테스트 골격)으로 몇몇 오래된 repo에 몰려 있었습니다(예: QuixBugs는 42개 중 14개였고, 이것과 다른 static repo는 제외). 이 글의 모든 수치는 genuine 기준입니다. task당 격차는 어느 기준으로 봐도 거의 안 바뀝니다(genuine ~4.6×, flagged ~4.8×). over-count가 양쪽에 거의 비례적이었기 때문입니다.
- 이건 census가 아니라 sample입니다. 이 글의 모든 수치는 우리가 실제로 audit한 benchmark, 즉 Harbor index의 agentic seed benchmark + 별도로 손으로 고른 잘 알려진 static benchmark에서 나온 것이지, 세상의 모든 benchmark에서 나온 게 아닙니다. 그래서 “star 상위 10개”는 그 set 안에서 가장 star 많은 10개를 뜻하고, 우리가 아직 index 안 한 더 유명한 benchmark는 그 밖에 있어 leaderboard·count·평균을 바꿀 수 있습니다. 여기 숫자는 전부 “우리가 다루는 benchmark에 대한 측정”으로 읽어 주세요. 그 범위는 계속 넓히는 중입니다.
- Counting unit은 individual comment가 아니라 parent Issue/PR thread.
- “fixing”은 open PR로 근사합니다. thread 단위로 세기 때문에, 보고된 Issue와 그 진행 중 PR은 open 1 + fixing 1로 잡힙니다. Issue→open-PR linkage를 신뢰성 있게 못 잡아 합치지 않습니다.
- Task-normalized 비교. 각 class에서 GitHub star 상위 10개를 골랐고(defect 수가 아니라 인기 기준이라 측정 대상 그 자체로 표본을 고르지 않습니다), 각 benchmark의 task 수는 repo·논문을 직접 읽어 셌습니다(채점되는 단일 항목 = 1 task). ~4.6×는 directional입니다: 두 평균 모두 작은-task outlier 하나씩(terminal-bench; ARC-AGI-2)에 기대고, 어느 쪽을 빼도 격차는 같은 방향으로 몇 배입니다. per-task chart에서 task 비교 불가로 제외: 48-project monorepo(DAMO-ConvAI), 52k 합성 set(SWE-smith), 절차생성기(reasoning-gym), BIG-bench(task 204), 경계선상의 single-shot+execution harness 몇 개.
- Launch timing은 GitHub repo
created_at기준이라 논문/공식 release date와 다를 수 있음; 시간축은 “repo가 공개된 뒤의 activity”로 읽을 것. - 이 시리즈 다른 글에서 인용한 외부 수치(SWE-bench Verified 재감사, DeepSWE/SWE-bench Pro 확인)는 우리 dataset이 아니라 해당 팀의 public report.
