The defect loop: capture, audit, surface, re-eval
Benchmarks get patched and the target keeps moving, but leaderboards almost never say which version they ran. This is the whole loop we built to fix that: capture every defect, audit it into one open store, surface it everywhere, and eval around it.
When Terminal-Bench shipped 2.1, it patched 28 of its 89 tasks, and every model's score jumped 6 to 12 points. Opus 4.6 gained 12.1. Nobody shipped a better model that week; the ruler changed. (Credit to the Terminal-Bench team: they versioned it and published every delta. Most benchmarks just patch tasks silently, in place.)
So scores from before and after a fix aren't the same measurement, and leaderboards and system cards almost never say which commit they ran. The ranking mostly held in that release, but the margins didn't: a number measured once on the buggy version and then frozen doesn't survive a patch that moves every score by double digits.
This keeps happening: benchmarks have defects, the defects get fixed, and the target keeps moving. To compare anything fairly you need two things that don't exist today: a shared, live record of which tasks are broken, and a way to eval around it.
Today the record is GitHub, and that's not enough
Right now that record is GitHub issues and PRs. It's the right place for the discussion and the patch, and it should stay there. But the real defects are buried under docs, feature requests, and the one thread that quietly breaks six tasks. They are scattered across every repo, with no live status. GitHub holds the conversation and the merge; it doesn't hold the benchmark. An issue can't carry the task it breaks, the version it affects, the trajectory that exposed it, or its effect on the score.
So we built the whole loop instead: capture every defect → audit it into one open store → surface it everywhere → re-eval continuously.
Capture & curate → Open Defect
Defects come from two places: those upstream GitHub threads, and /report-defect, one command when you hit a broken task mid-eval, with the agent's trajectory attached as evidence. An LLM reads each source, drops the noise, splits the multi-task threads, and writes one clean record per task: root-caused, evidence-linked, and PR-correctable.
The result is Open Defect, a public ledger organized by task. As of this writing it holds 465 confirmed defects across 40 of the 72 benchmarks we track: 62 still open, 48 with a fix in flight, 355 fixed. Each record carries where the defect sits in the loop and the upstream thread it came from. A typical entry: SWE-bench Verified's sympy-13031, where the problem statement asks the model to fix DenseMatrix but the gold patch changes SparseMatrix, a different class, so the task and its “correct” answer don't match (issue #514).
It's open and PR-correctable: a wrong or missing entry can be fixed with a pull request. The platform is ours; the data is open.
Surface it wherever you work
A defect record is only useful where you'd hit the defect. So the same store surfaces four ways:
- README health badge: a live found → fixing → fixed status for your benchmark's README, so “maintained” is visible, not assumed.
- Delphik Web: browse every defect at posttrain.dev/benchmarks.
- Raw JSON: the whole ledger, in the repo.
- CLI (
pip install delphik): pull the open-defect set straight from your terminal, hold out the broken tasks, pin the version, and run your own fair eval.
The CLI is live today. It reads the open-defect repo directly and emits the exact Harbor exclude arguments you need, so you can hold out broken tasks and run a clean, version-pinned eval without waiting on anyone's leaderboard.
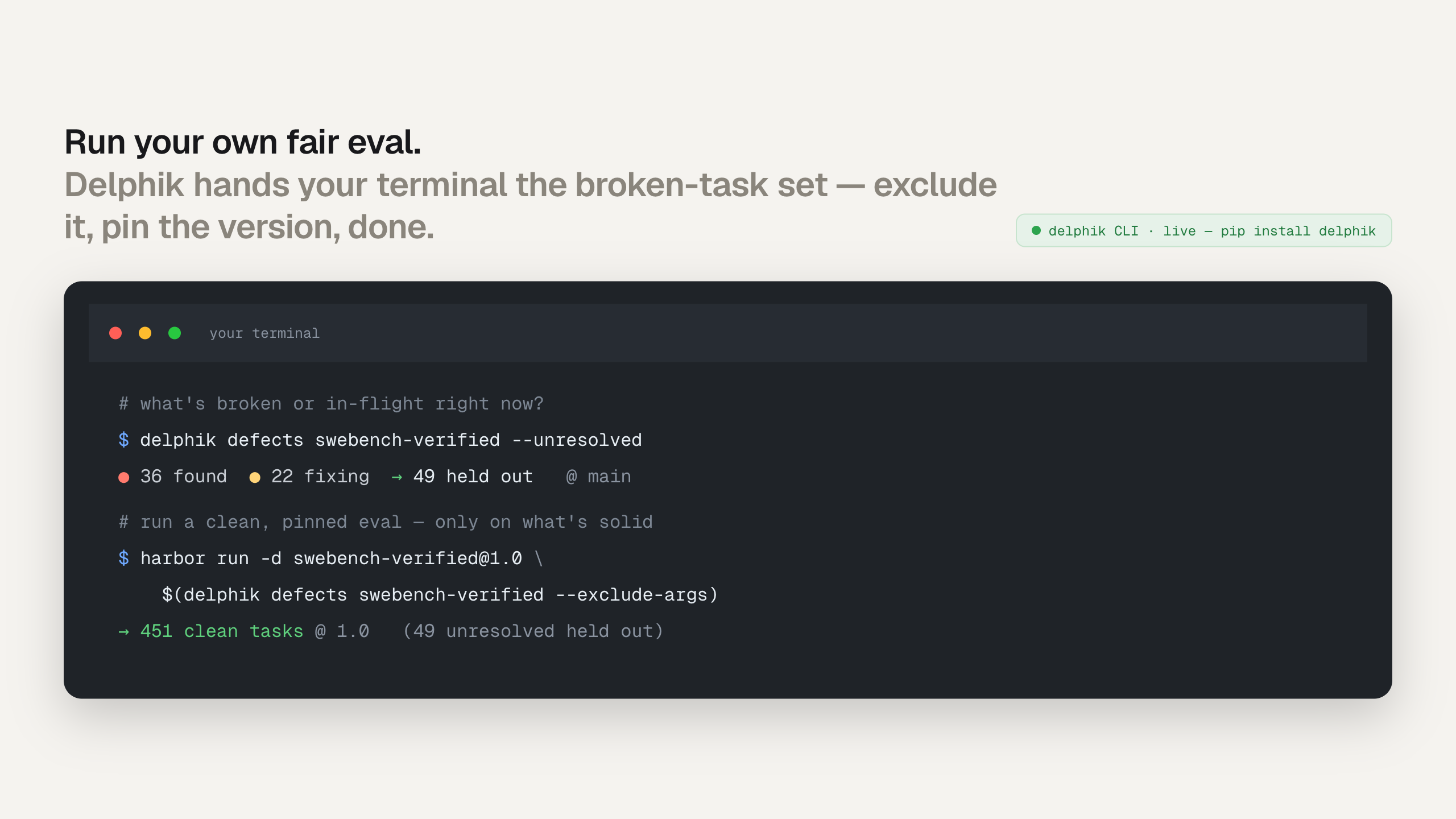
delphik defects <benchmark> lists what's broken or in flight and feeds it straight into a version-pinned Harbor run. (Illustrative; counts vary as the ledger updates.)What we're building: continuous, task-level eval
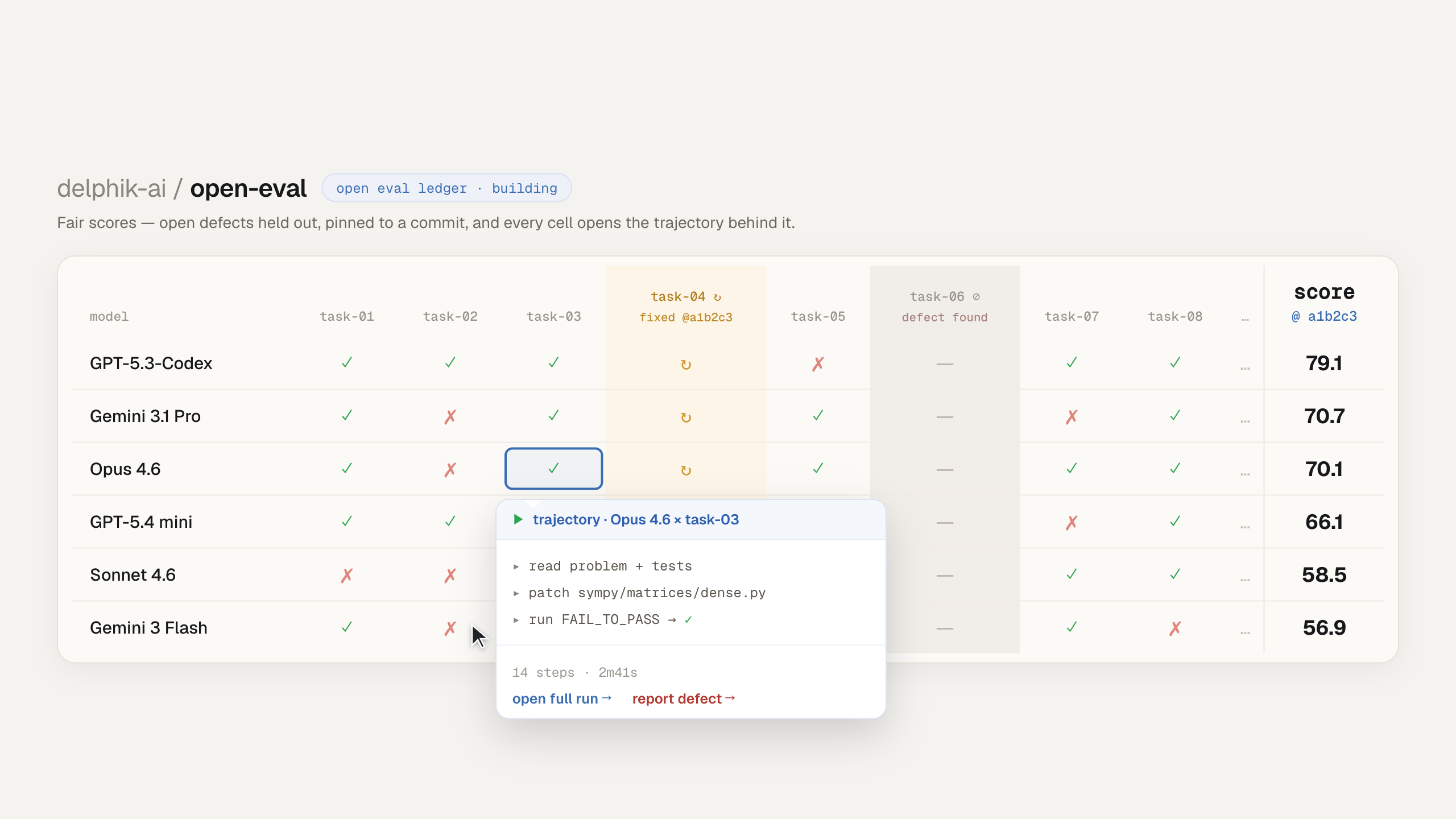
The payoff is a leaderboard that can't be quietly moved by a patch. Open defects are held out of the score; the moment one is fixed, we re-run just that task, for every model, and pin every score to a commit id. So any two models are always compared on the same clean set, and a 2.0-vs-2.1 mismatch can't silently shift the ranking. Every result stays auditable too: click any pass or fail to open the agent's full trajectory.
And the leaderboard itself will be open: a public repo anyone can reproduce, verify, or add their own runs to, not a black box you have to trust. This part is still being built; the Open Defect ledger, the health badge, and the CLI are what's live today.
Try it
It's all open and still early, so feedback, corrections, and PRs are welcome.
- Browse the defects: github.com/delphik-ai/open-defect · posttrain.dev/benchmarks
- Run a clean eval:
pip install delphik, thendelphik defects <benchmark> - Report the next broken task you hit:
npx skills add delphik-ai/delphik --skill report-defect
This is the third piece of a series on benchmark quality: who finds the defects, what happens after they're found, and, here, the loop that ties capture to a fixed score.
