Agentic benchmark를 고치고 있는 숨은 공헌자들
62개 benchmark repo의 GitHub thread 6,245개를 읽고, 이 benchmark들을 조용히 굴러가게 유지하는 744명을 찾았습니다. 그들에게 보내는 shoutout, 그리고 그 뒤의 데이터입니다.
coding benchmark의 무엇이 문제인지에 대해서는 이미 꽤 많이 썼습니다. 맞는 코드를 reject하는 verifier, 새어 나간 solution, 어떤 agent도 풀 수 없는 task. 그리고 그걸 모델이 대신 audit해줄 수 있는지에 대해서도요. (짧게 말하면, triage에는 도움이 되지만 사람을 대체하진 못합니다. 여기에 정리해 뒀습니다.)
이 글은, 우리끼리 얘기는 했지만 한 번도 실제로 측정해 본 적 없는 질문에 관한 것입니다. 누가 이 benchmark들을 실제로 굴러가게 유지하고 있고, 왜 그 일이 이렇게까지 비싸야 할까요?
분명히 누군가는 하고 있습니다. 좋은 benchmark는 적극적으로 maintain됩니다. SWE-bench와 Terminal-Bench는 defect가 드러나는 대로 fix를 ship하지만, 그런데도 defect는 계속 나오니, maintenance는 사실상 멈추지 않습니다. 그 작업은 실제 노동이고, 대부분 GitHub 위에서 공개적으로 일어나며, 그 상당 부분은 논문에 이름이 올라간 사람들이 하는 게 아닙니다. 그래서 추측을 멈추고 세어 봤습니다.
agentic benchmark repo 62개에서 parent GitHub Issue/PR thread 6,245개를 읽고, 그중 1,874개를 benchmark defect 또는 probable defect로 분류했으며, 그 뒤에 있는 public auditor 744명을 추적했습니다. 어떤 maintainer roster에도 없으면서 Issue를 열거나, fix PR을 올리거나, 또는 둘 다 한 사람들입니다.
이 글은 그 사람들에게 보내는 shoutout입니다.
Discovery는 대부분 repo 바깥에서 옵니다
GitHub author association이 OWNER, MEMBER, COLLABORATOR가 아닌 사람을 public auditor, 그 외를 repo-team author로 나눠 누가 무엇을 하는지 봤습니다.
| 분류 | defect thread | PR | Issue | resolved |
|---|---|---|---|---|
| public auditor | 1,290 | 574 | 716 | 487 |
| repo-team author | 583 | 440 | 143 | 462 |
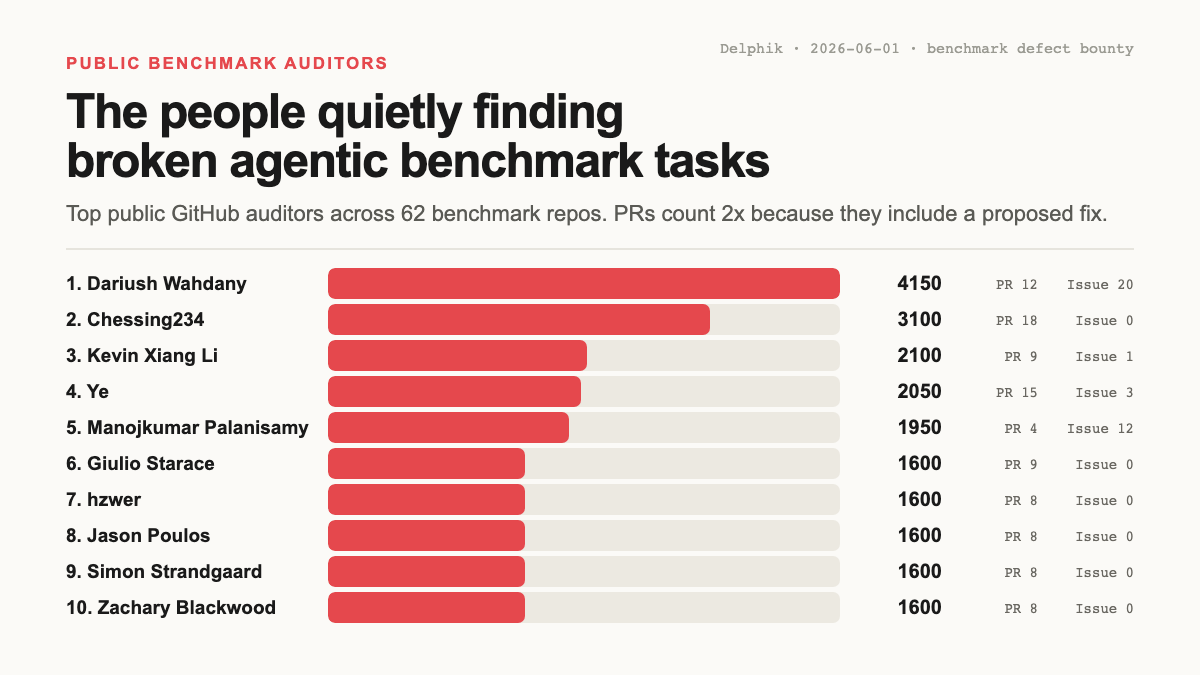
Public auditor가 올린 defect thread는 전체로 보면 repo team의 약 2.2배입니다. 그런데 종류별로 쪼개면 격차가 한쪽으로 쏠립니다. “이거 깨졌다”는 신고에 해당하는 Issue는 716개 vs 143개로 약 5배, 직접 고쳐 올린 PR은 574개 vs 440개로 약 1.3배. 다시 말해 public auditor는 고치는 것보다 찾아내는 것에서 repo team을 훨씬 더 앞섭니다. project 바깥의 사람들이, 보고되는 것의 대부분을 발견합니다.
반대로 closing은 repo team이 대부분 합니다. merged PR 비율이 높고, 자기 앞에 온 thread를 더 많이 resolve합니다. 그래야 맞는 일입니다. Loop는 보통 commit 권한과 context를 쥔 project 안에서 닫혀야 하니까요.
그러니 이건 auditor 대 maintainer 구도가 아닙니다. 이미 잘 굴러가는 분업입니다. 바깥 사람들이 점검되는 surface를 넓히고, 팀이 fix를 landing하고, benchmark는 매 pass마다 조금씩 나아집니다. 제약은 이 일을 할 사람이 부족하다는 게 아닙니다. Fix 하나 주변의 모든 게 흩어져 있다는 것, 뒤에서 다루겠지만 그게 보고 한 건의 비용을 필요 이상으로 키웁니다.
Top 10
| # | auditor | score | defect | PR | Issue | 연락처 |
|---|---|---|---|---|---|---|
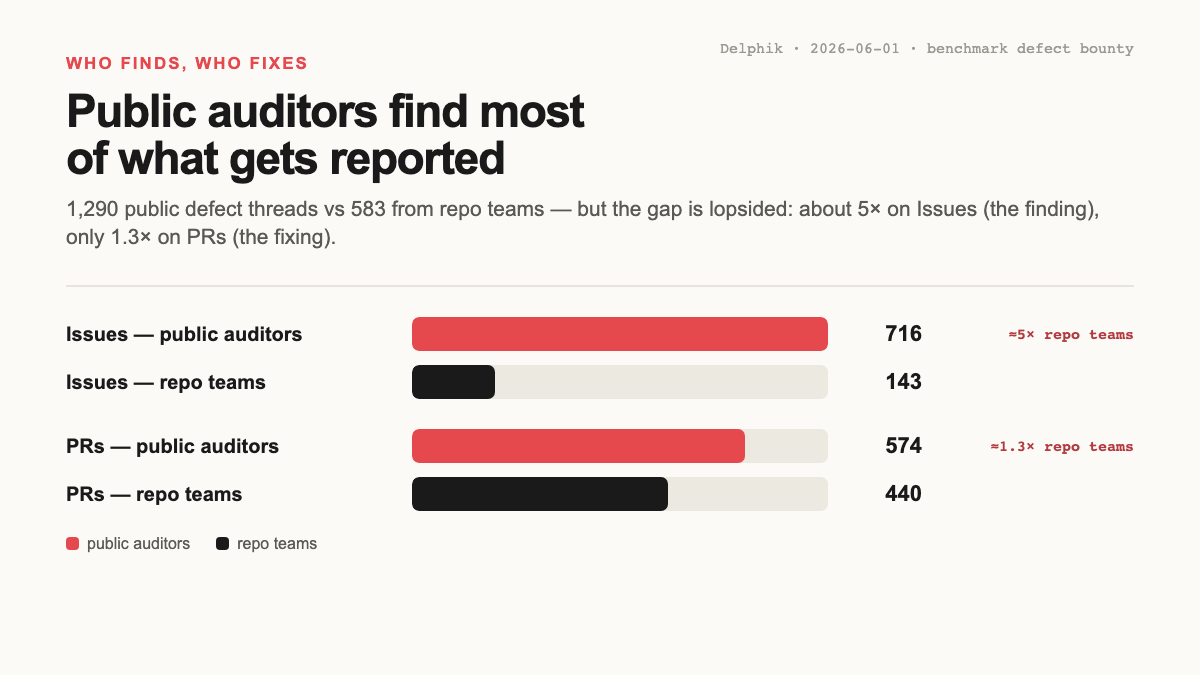
| 1 | Dariush Wahdany | 4,150 | 32 | 12 | 20 | @dwahdany |
| 2 | Chessing234 | 3,100 | 18 | 18 | 0 | GitHub |
| 3 | Kevin Xiang Li | 2,100 | 10 | 9 | 1 | @kevin_x_li |
| 4 | Ye | 2,050 | 18 | 15 | 3 | heye.me |
| 5 | Manojkumar Palanisamy | 1,950 | 16 | 4 | 12 | @smartmanoj42857 |
| 6 | Giulio Starace | 1,600 | 9 | 9 | 0 | @thelokasiffers |
| 7 | hzwer | 1,600 | 8 | 8 | 0 | @hzwer |
| 8 | Jason Poulos | 1,600 | 8 | 8 | 0 | poulos.ai |
| 9 | Simon Strandgaard | 1,600 | 8 | 8 | 0 | @SimonStran36407 |
| 10 | Zachary Blackwood | 1,600 | 8 | 8 | 0 | @blackaryz |
점수는 PR을 Issue의 2배로 봅니다. PR은 단순한 flag가 아니라 누군가 실제로 시도한 repair를 담고 있기 때문입니다. 여러 benchmark에 걸쳐 활동하면 작은 bonus가 붙되, breadth가 depth를 덮지 못하도록 상한을 뒀습니다. 그리고 merge 여부는 의도적으로 무시합니다. 조용한 repo에 올라간 unmerged PR도 누군가 일을 한 것이니까요. 그래서 fix가 landing됐는지는 ranking에 섞지 않고 따로 추적합니다. 전체 식은 본문 마지막에 있습니다.
명단은 지금 활발한 benchmark들과 깔끔하게 겹칩니다. terminal-bench와 v2, SWE-bench family, ARC-AGI-2, ade-bench, frontier-evals. 몇몇은 자기 영역의 단골이고, 몇몇은 한 번 등장해 진짜 문제를 잡아 잘 정리해 올린 사람입니다. 둘 다 여기 속합니다.
이제 모델이 그냥 해주면 되지 않나?
744명이 손으로 하고 있으니 당연히 따라오는 질문입니다. 그래서 직접 테스트했고, 결과는 따로 (여기) 정리했습니다. 이 글에 중요한 부분만: LLM auditor는 broken task 거의 전부를 flag하지만, 가장 중요한 defect, 즉 prompt가 자기 test와 어긋나는 종류가 아니라 drift하는 image나 새어 나간 solution 같은 infrastructural한 것들에서는 full environment를 줘도 원인을 틀리게 짚는 경우가 더 많습니다. Benchmark를 탓하기 전에 자기 attempt를 먼저 탓하는 경향이 있습니다.
핵심은 이겁니다. 진단하기 가장 어려운 layer가, standalone auditor가 가장 못 다루고 eval을 직접 돌린 사람이 가장 잘 다루는 layer입니다. 깨질 때 trajectory를 눈앞에 두고 거기 있었기 때문입니다. 이 list의 744명은 자동화가 올 때까지 자리를 지키는 게 아닙니다. 자동화되지 않는 부분을 하고 있습니다.
왜 이들에게 필요 이상으로 비싼가
마찰은 진단이 아니라 그 주변 전부에 있습니다. Benchmark defect 하나는 결국 대여섯 군데에 흩어집니다: 처음 surface된 trajectory, local note, GitHub Issue, follow-up PR, maintainer의 답글, 그리고 운이 좋으면 fix가 실제로 들어간 release. 그중 GitHub patch loop만 tooling이 좋습니다. 그걸 하나로 묶는 benchmark-specific한 맥락(어떤 task, 어떤 version, 어떤 run에서 잡혔는지, fix가 사람들이 실제로 돌리는 version까지 갔는지)은 한 곳에 모이지 않습니다.
위 사람들이 그만큼 고생해야 했던 이유의 대부분이 이것입니다. 좋은 benchmark defect report는 Issue 하나가 아닙니다. 내 agent 탓이 아니라 task 탓인지 확인하려 eval을 다시 돌리고, trajectory를 읽을 만하게 줄이고, fork와 registry 사이에서 맞는 repo를 찾고, 맞는 maintainer를 찾고, 정리해 쓰고, 그리고 몇 주 뒤 fix가 ship되긴 했는지 확인하는 일입니다. 각 단계는 작습니다. 쌓이면, broken task를 만난 사람 대부분이 조용히 지나치고 아무것도 올리지 않을 만큼이 됩니다.
개인 비용 위에 또 하나가 있습니다. 이 모든 게 한 곳에 추적되지 않다 보니, 같은 일이 다시 반복됩니다. 누군가 fork나 Discord에서 진단해 보고한 defect가 다음 팀에는 보이지 않고, 그 팀은 한 분기 뒤 그걸 다시 발견하느라 compute를 태웁니다. Maintenance는 일어나고 있습니다. 다만 한데 모이지 않아서, field가 같은 fix에 두 번 이상 비용을 치를 뿐입니다.
Defect Hub는 어디에 들어가나
이게 Defect Hub가 메우려는 gap이고, 이 744명이 바로 그 대상입니다. GitHub에서 무언가를 옮겨오지 않습니다. merge와 논의는 maintainer에게 그대로 둡니다. 다만 defect의 전 생애에 걸쳐 benchmark-specific한 맥락을 한데 붙들어 둡니다: agent가 만난 그 순간 trajectory를 붙여 capture하고, task와 version에 고정하고, 맞는 maintainer로 route하고, fix가 실제로 ship될 때까지 추적합니다. 전체 작동 방식은 launch post에 있습니다. 노리는 건 두 가지입니다. 하나, defect 하나를 신고하는 데 드는 수고가 점점 줄어드는 것. 둘, 한 번 검증돼 고쳐진 defect는 open record로 남아서, 다음 팀이 같은 걸 다시 발견하느라 헤매는 대신 그냥 인용할 수 있는 것.
이 글을 제품 얘기보다 먼저 쓴 건 의도된 것입니다. 우리가 돕고 싶은 일은 이미 일어나고 있고, 이 dataset의 744명이 agentic benchmark가 버티는 큰 이유입니다. 이 list에 있다면, 감사합니다. 아는 사람이 있다면, 이 글을 전해 주세요.
Methodology
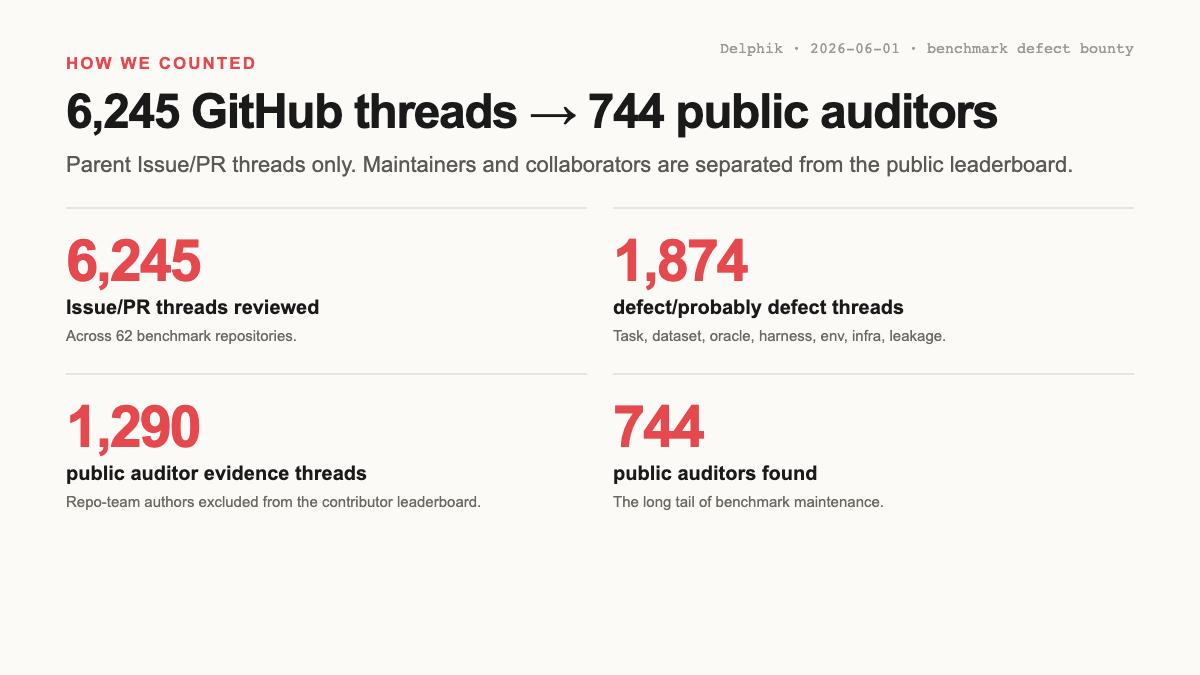
2026-06-01 snapshot 기준, 62개 agentic benchmark repo의 parent GitHub Issue/PR thread 6,245개를 검토했습니다.
- 1,874개 thread를 defect 또는 probable defect로 분류.
- 1,290개는 public auditor 작성 (PR 574 / Issue 716), 744명이 작성.
- 583개는 repo-team author 작성 (PR 440 / Issue 143), benchmark health signal로는 유지, public-auditor leaderboard에서는 제외.
Score:
evidence_score = 200 * defect_PR
+ 100 * defect_Issue
+ 100 * probably_defect_PR
+ 50 * probably_defect_Issue
leaderboard_score = evidence_score + repo_diversity_bonus
repo_diversity_bonus = +200 per extra benchmark repo, max +600Caveats:
- Counting unit은 individual comment가 아니라 parent Issue/PR thread.
- Repo-team author는 GitHub author association(
OWNER,MEMBER,COLLABORATOR)으로 분리하고, bot도 leaderboard에서 제외합니다. - PR 점수는 merge 여부와 독립. Merged PR은 loop를 닫지만, unmerged PR도 누군가 시도했다는 evidence입니다.
- Closed thread를 자동으로 fixed로 세지 않습니다. Closed-unmerged PR, merged PR 연결 없이 닫힌 Issue는 별도 resolution gap bucket으로 둡니다.
- 2026-06-01 기준 public GitHub surface audit입니다. 이제까지의 모든 benchmark defect에 대한 all-time claim이 아닙니다.
빠진 사람이 있다면, 744명 list에서는 거의 확실히 있을 텐데, 알려주시면 추가하겠습니다.
